基础介绍
Hologres利用混合行/列存储来优化HSAP(Hybrid serving and analytical processing)中使用的点查询,列扫描和数据摄取等操作。 执行上下文作为系统线程和用户任务之间的资源抽象。 执行上下文可以以很少的上下文切换开销进行写作调度。 查询被并行化并映射到执行上下文以进行并发执行。
调度框架强制执行不同查询之间的资源隔离,并支持可定制的调度策略。
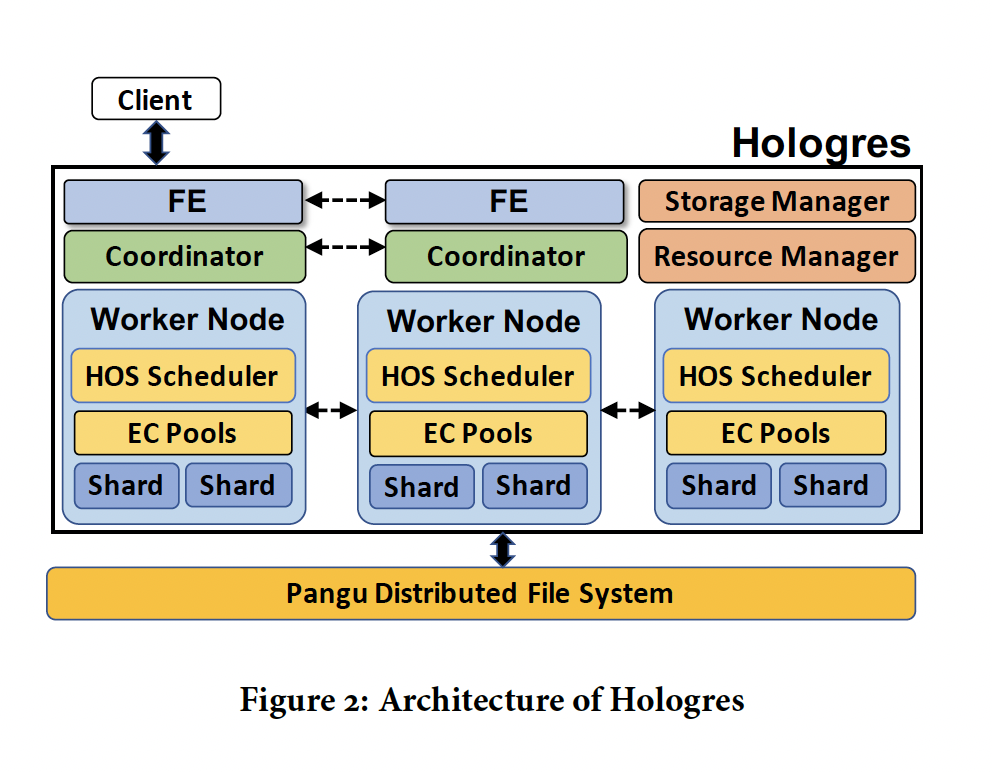
存储设计 hologres采用了一种将存储与计算解耦的架构.数据远程保存在云存储中。 Hologres以表组的形式管理表,将一个表组划分为多个分片.每个分片都是独立的 manages独立读写 与物理工作节点解耦,数据分片可以在工作节点之间灵活迁移,hologres以数据分片作为基本数据管理单元, 通过分片迁移高效实现故障恢复,负载均衡,集群扩容。
Hologres使用tablet结构来统一存储表.Tablets可以是行格式或列格式,并且都以类似LSM的方式进行管理,以最大化写入吞吐量,并最小化数据摄取的延时。
HOS调度框架 执行上下文是协同调度的,上下文切换开销很小.HOS通过将查询划分为细粒度的工作单元并将工作单元映射到执行上下文来并行化查询执行。 该架构可以充分发挥硬件高并行性的潜力,使我们能够同时多路复用大量查询
Hologres 具有新颖的存储设计,以及名为HOS的高效资源管理和调度层.这些新颖的设计组合帮助hologres实现实时摄取,低延迟服务,交互式分析处理,还支持其他系统的联合查询执行。
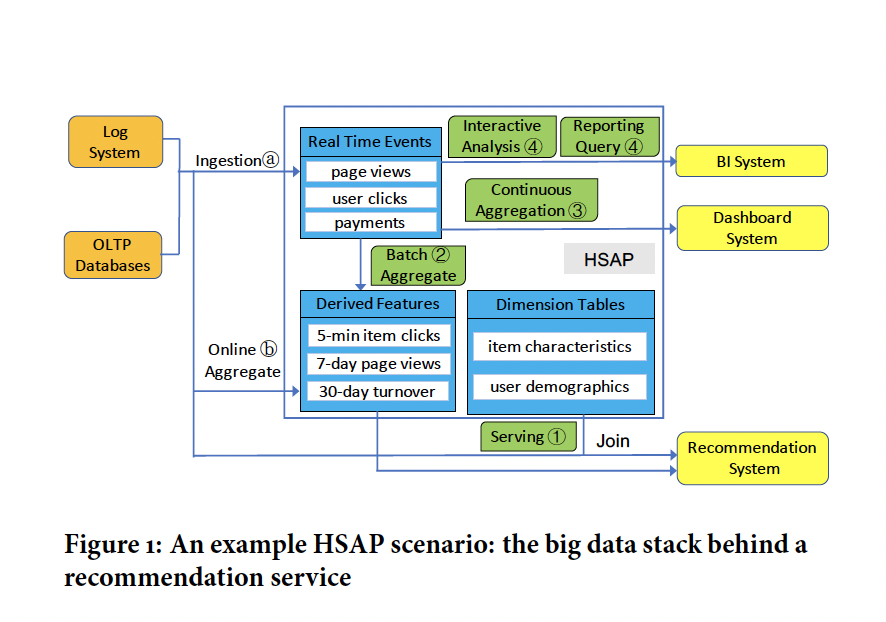
存储
 存储管理器维护一个表组分片目录,以及它们的元数据,如物理位置和键范围,每个Coordinator都会缓存这些元数据的本地副本,以方便查询请求的调度 Hologres 允许执行单个查询来跨越hologres和其他查询引擎
存储管理器维护一个表组分片目录,以及它们的元数据,如物理位置和键范围,每个Coordinator都会缓存这些元数据的本地副本,以方便查询请求的调度 Hologres 允许执行单个查询来跨越hologres和其他查询引擎
Hologres支持为HSAP场景量身定制的混合行列存储布局,行存储针对低延迟点查找进行了优化,列存储在执行高吞吐量列扫描
数据模型
hologres 每个表都有一个用户指定的clusterid,和unique 行定位器,如果clusterid是唯一的,则直接用作行定位符,否则 将uniqueid附加到clusterid以构成定位器,即(clusterid,uniqueid)
数据库中所有表都分组为table groups,一个表组被分片成多个表组分片(tgs), 其中每个TGS包含每个表的基础数据分区和所有相关索引的分区.我们将基础数据分区和索引分区统一视为一个tablet. tablet有两种存储格式:行tablet和列tablet,分别针对点查找和顺序扫描进行了优化。基础数据和索引可以存储在行表,列表或两者中。
tablet中需要有一个唯一的密钥,因此,基本数据表的键是行定位符.而对于二级缩影的tablet,如果索引是唯一的,则索引列作为tablet的键,否则,
Table Group Shard TGS
 hologres中数据管理的基本单位。一个TGS主要由一个WAL manager和属于这个TGS中的table shards的多个tablet组成
hologres中数据管理的基本单位。一个TGS主要由一个WAL manager和属于这个TGS中的table shards的多个tablet组成
Tablets 被统一管理为一颗LSM树:每个tablet由worker节点内存中的一个内存表,以及一组持久化在分布式文件系统中的不可变分片文件组成 文件被组织为多个级别,Level0,Level1,….,LevelN. 在Level0中,每个分片文件对应一个 flushed内存表 从Level1开始,本层的所有记录按key排序划分到不同的shard文件中,这样同一层的不同shard文件的key范围是不重叠的。 Leveli+1可以容纳比Leveli多K倍的分片文件,每个分片文件的最大大小为M。
tablet还维护一个元数据文件,用于存储其分片文件的状态。元数据文件按照与RocksDB 类似的方法进行维护,并保存在文件系统中
由于记录是版本化的,因此TGS中的读写完全分离,最重要的是,采用的是无锁的方式,只允许WAL的单个写入者,但当前在TGS上允许任意数量的读者。 由于HSAP场景对一致性的要求比HTAP弱,hologres选择只支持原子写和read-your-writes读来实现读写的高吞吐和低延迟
写入TGS
hologres支持两种写入:单分片写入和分布式批量写入。两种类型的写入都是原子的。即写入提交或回滚。 单分片写入一次更新一个TGS,并且可以以极高的速率执行.另一个方面,分布式批量写入用于将大量数据作为单个事务转存到多个TGS中,并且通常会以比较低的批量执行。
单片写入
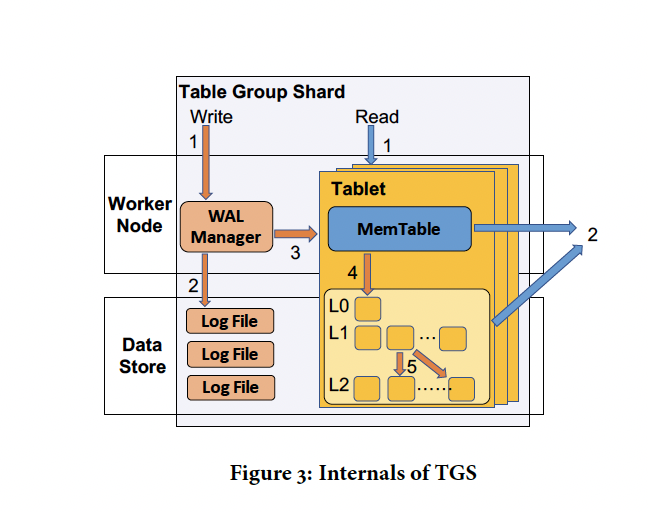 在接收到单个分片写入时,WAL管理器 为写请求分配一个LSN,他由时间戳timestamp和递增的序列号increasing sequence number组成,并创建一个新的Log entry 保存进入 文件系统。log entry包含 重播log的写入的必要的信息。写入在其日志完全持久化后提交,写请求的在tablet的内存表中,并对新的读取请求可见, 不同tablet的更新可以并行进行. 一旦内存表已满,将其作为文件系统中的分片文件使用,并初始化一个新的。
在接收到单个分片写入时,WAL管理器 为写请求分配一个LSN,他由时间戳timestamp和递增的序列号increasing sequence number组成,并创建一个新的Log entry 保存进入 文件系统。log entry包含 重播log的写入的必要的信息。写入在其日志完全持久化后提交,写请求的在tablet的内存表中,并对新的读取请求可见, 不同tablet的更新可以并行进行. 一旦内存表已满,将其作为文件系统中的分片文件使用,并初始化一个新的。
最后分片文件将在后台异步压缩,在压缩或内存表刷新结束时,tablet的元数据文件会相应的更新。
分布式批量写入
采用两阶段提交机制在保证分布式批量写入的写入原子性
接收到batch写请求的FE节点将锁定所涉及的TGS中所有访问过的tablets。 每个TGS: 为该批写入分配一个LSN,刷新所涉及的tablet的内存表,以及加载数据并将它们作为分片写入, 可以通过构建多个内存表并将它们并行写入文件系统来进一步优化。一旦完成,每个TGS都会投票给FE节点。当FE节点收集到来自参与的TGS,它承认它们最终的提交或中止决定。 在收到提交决定后,每个TGS都会保留一个日志,指示该批写入已提交.否则,将删除该批写入过程中所有新生成的文件。 当两阶段提交完成后,相关tablet的锁就会被释放
读取TGS
hologres 支持行和列 tablet 多版本读取.读请求的一致性级别是 read-your-writes. 一个客户端总是能看到最新 committed write by itself. 每个读请求 包含 read timestamp,用来组装LSNread,这个LSNread用来过滤掉不可见的记录 i.e. records whose LSNs are larger than LSNread.
为了方便多版本读取,TGS为每个表维护一个LSNref,它存储 LSN 最旧的版本, LSNref根据用户设定 周期性的更新.在memory table flush 并且 file compaction,遵循两个规则,(1)合并的LSN等于或者小于LSNref的记录 (2)LSNs大于LSNref的记录保持原样
分布式TGS管理在我们目前的实现中,一个TGS的写入者和所有读取这共同位于同一个工作节点上,以共享这个TGS的内存表。 如果工作节点正在经历工作负载突发,Hologres支持将一些TGS迁移到过载的工作节点。
我们支持两种类型的只读副本: 1.完全同步的副本维护TGS的内存表和元数据文件的最新副本,并且可以服务于所有读取请求 2.部分同步的副本 仅维护元数据文件的最新副本,并且只能为写入文件系统的数据提供读取服务 可以根据读取版本将对TGS的读取分派到不同的副本 这两个只读副本都不需要复制分片文件,如果需要,分片文件会从分布式文件系统加载
如果TGS失败,存储管理器向资源管理器请求一个可用槽,同时向所有协调器广播TGS失败消息. 恢复TGS时,我们从最新的flushed LSN 重名WAL日志以重建其memory表.一旦所有的内存表都被完全重建,恢复就完成了。 之后,存储管理器得到确认,然后向所有协调器广播包含新位置的TGS恢复消息。协调器暂时保存对失败的TGS的请求,直到它恢复。
Column Tablet
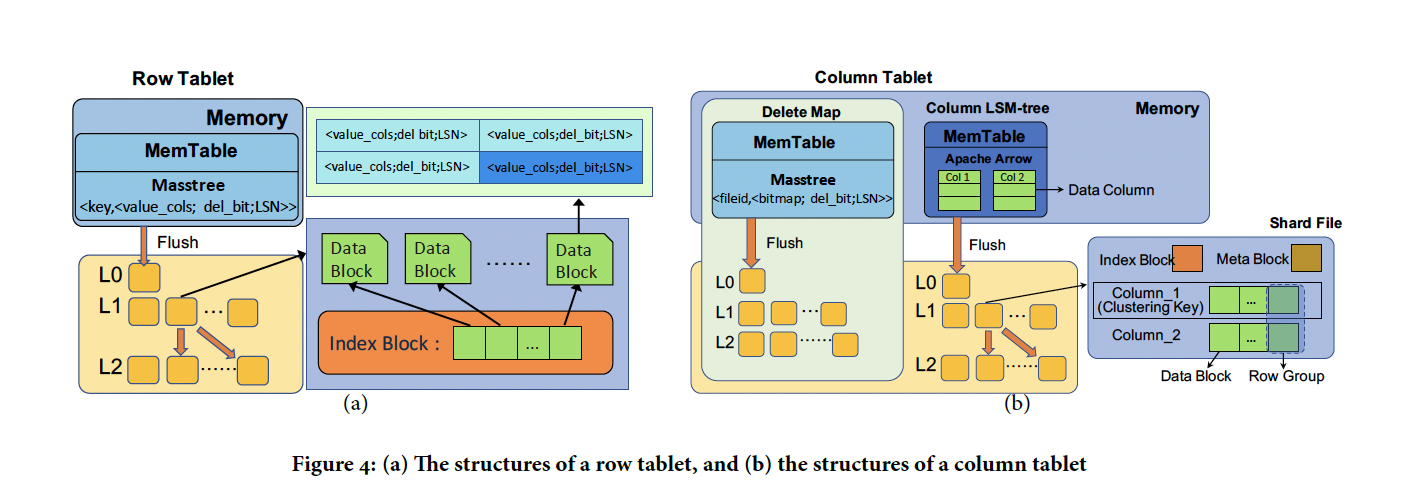
Row tablets 经过优化以支持给定键的有效点查找。 内存表维护为 Masstree,在其中我们按记录的键对记录进行排序.不同的是,分片文件是块式结构. 分片文件由两种类型的块组成:数据块和索引块. 分片文件中的记录按键排序。连续的记录被分组为一个数据块.为了帮助通过键查找记录,我们进一步跟踪每个数据块的起始键及其在分片文件中的集合 作为索引块中的一对key,block offset 为了支持多版本数据,存储再行tablet中的值被扩展为value cols,del bit,LSN value cols是非键列值,del位表示这是一条删除记录。 在行tablets中,插入或更新由键,列值和一个LSNwrite组成。一次删除包含一个键,一个特殊的删除标记和一个LSNwrite 每个写入都被转换成一对键值对的行表.对于插入和更新,del位设置为0. 对于删除,列字段为空,del位设置为1. 首先将键值对附加到内存表中.一旦内存表已满,他就会作为level0中的分片文件被写入文件系统,如果Leveli已满,则可能会进一步触发从Leveli到Leveli+1的级联压缩
ROW Tablet
列Tablet在促进列扫描,与行tablets不同,列tablet由两个组件组成,一个列LSM树和一个删除映射。 存储在列LSM树中的值以格式扩展 of:value cols,LSN 其中value cols 为非键列,LSN为对应的写LSN.在一列LSM树中
内存表以Apache Arrow 的格式存储记录 记录按到达顺序连续添加到内存表中。在分片文件中,记录按照键排序并按逻辑分成行组。行组中的每一列都存储为单独的数据块。 同一列的数据库连续存储在分片中,以方便顺序扫描。我们在元块中维护每一列的元数据和整个分片文件,以加速大规模数据检索。 元快存储:(1) 对于每一列,数据块的集合,每个数据块的取值范围和编码方案,以及 对于分片文件,压缩方案,总行数,LSN和关键范围。为了根据给定的键快速定位行,我们将行组的排序后的第一个键存储在索引块中。
delete map 是一个row tablet,key是column LSM tree 中的一个shard id,value是一个bitmap 表示哪些记录是新删除的分片文件中相应的LSN 在delete map的帮助下,column table 可以大规模并行化顺序扫描
读取列片.对列tablet的读取操作包括目标列和LSNread.读取结果是通过扫描内存表和所有的分片文件得到的 在扫描分片文件之前,我们将LSN范围与LSNread进行比较 1.如果其最小LSN大于LSNread,则跳过该文件 2.如果其最大LSN,在读取版本中可见 3 否则,只有该文件中记录的子集在读取版本中
第三种情况,我们扫描该文件的LSN列并生成一个LSN(log sequnece number)位图, 指示哪些行在读取版本中可见。为了过滤掉分片文件中已删除的行,我们在删除映射中执行读取, 使用分片文件的ID作为版本LSNread的键,其中合并操作合并所有候选的bitmap,获得的位图与LSN位图相交, 并与目标数据块连接,以过滤掉读取版本中已删除和不可见,而无需与其他级别的分片文件合并,因为delete map 可以有效地告诉分片文件中 直到LSNread的所有已删除行。
写入Column Tablets。在列表中,插入操作由一个键,一组列值和一个LSNwrite 组成。 Delete 操作指定了要删除的行的key,通过它 我们可以快速的找出包含该行的文件ID以及它在该文件中的行号。 我们在delete map 中执行 insert at version LSNwrite,其中key是文件ID,value是行号删除的行,更新操作的实现方式是先删除再插入。 对列LSM树的插入和删除map 可以出发内存表flush和shardid 压缩
分层缓存hologres采用分层缓存机制
降低I/O 和计算成本。一共有三层缓存,分别是本地磁盘缓存,块缓存和行缓存。
每个tablet 对应一组存储再分布式文件系统中的分片文件.本地磁盘缓存用于在本地磁盘(SSD)中缓存分片文件,以减少文件系统中昂贵的I/O操作的频率 在SSD缓存之上,内存中的块缓存用于存储最近从分片文件中读取的块。由于服务和分析工作负载具有非常不同的数据访问模式,我们在物理上隔离了行和列片的块 缓存.在块缓存之上,我们进一步维护一个内存中的行缓存,以将最近点查找的合并结果存储在行片中
查询执行
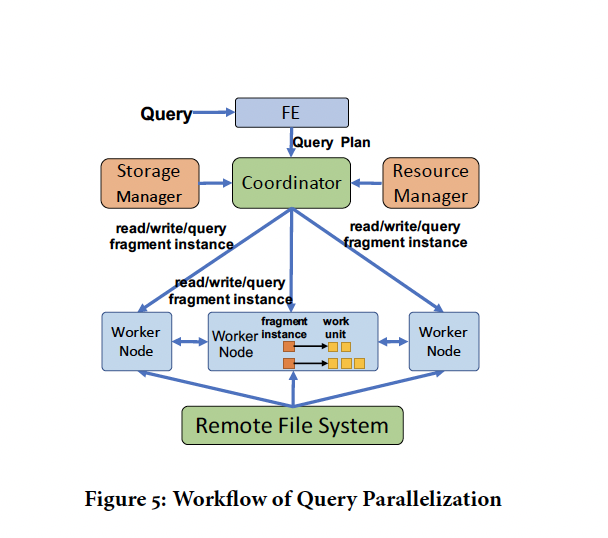
ARROW
masstree
https://zhuanlan.zhihu.com/p/271740123
LSM
https://zhuanlan.zhihu.com/p/181498475
bitmap
https://www.cnblogs.com/cjsblog/p/11613708.html
boomfilter
###列存 如果表是列存,那么数据将会按照列的形式存储。 列存默认使用ORC格式,采用各种类型的Encoding算法(如RLE、字典编码等)对数据进行编码,并且对编码后的数据应用主流压缩算法(如Snappy、 Zlib、 Zstd、 Lz4等)对数据进一步进行压缩,并结合Bitmap index、延迟物化等机制,提升数据的存储和查询效率。
系统会为每张表在底层存储一个主键索引文件,详情请参见主键Primary Key。 列存表如果设置了主键PK,系统会自动生成一个Row Identifier(RID),用于快速定位整行数据,同时如果为查询的列设置合适的索引(如Distribution Key、Clustering Key等),那么就可以通过索引快速定位到数据所在的分片和文件,从而提升查询性能,因此列存的适用范围更广,通常用于OLAP查询的场景
###行存 如果Hologres的表设置的是行存,那么数据将会按照行存储。 行存默认使用SST格式,数据按照Key有序分块压缩存储,并且通过Block Index、Bloom Filter等索引, 以及后台Compaction机制对文件进行整理,优化点查查询效率。
###行列共存 在实际应用场景中,一张表可能用于主键点查,又用于OLAP查询,因此Hologres在V1.1版本支持了行列共存的存储格式。行列共存同时拥有行列和列存的能力,既支持高性能的基于PK点查,又支持OLAP分析。数据在底层存储时会存储两份,一份按照行存格式存储,一份按照列存格式存储,因此会带来更多的存储开销。 数据写入时,会同时写一份行存格式和写一份列存格式,只有两份数据都写完了才会返回成功,保证数据的原子性。 数据查询时,优化器会根据SQL,解析出对应的执行计划,执行引擎会根据执行计划判断走行存还是列存的查询效率更高,要求行列共存的表必须设置主键: 对于主键点查场景(如select * from tbl where pk=xxx语句)以及Fixed Plan加速SQL执行场景,优化器会默认走行存主键点查的路径。 对于非主键点查场景(如select * from tbl where col1=xx and col2=yyy语句),尤其是表的列很多,且查询结果需要展示很多列,行列共存针对该场景,优化器在生成执行计划时,会先读取列存表的数据,读取完成后根据列存键值Key查询行存表的数据,避免全表扫描,提升非主键查询性能。该场景能充分发挥行列共存的优势,提高数据的快速检索性能。 对于其他的普通查询,则会默认走列存。
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2023/03/10/hologres-%E5%9F%BA%E7%A1%80%E4%BB%8B%E7%BB%8D/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)