现有问题
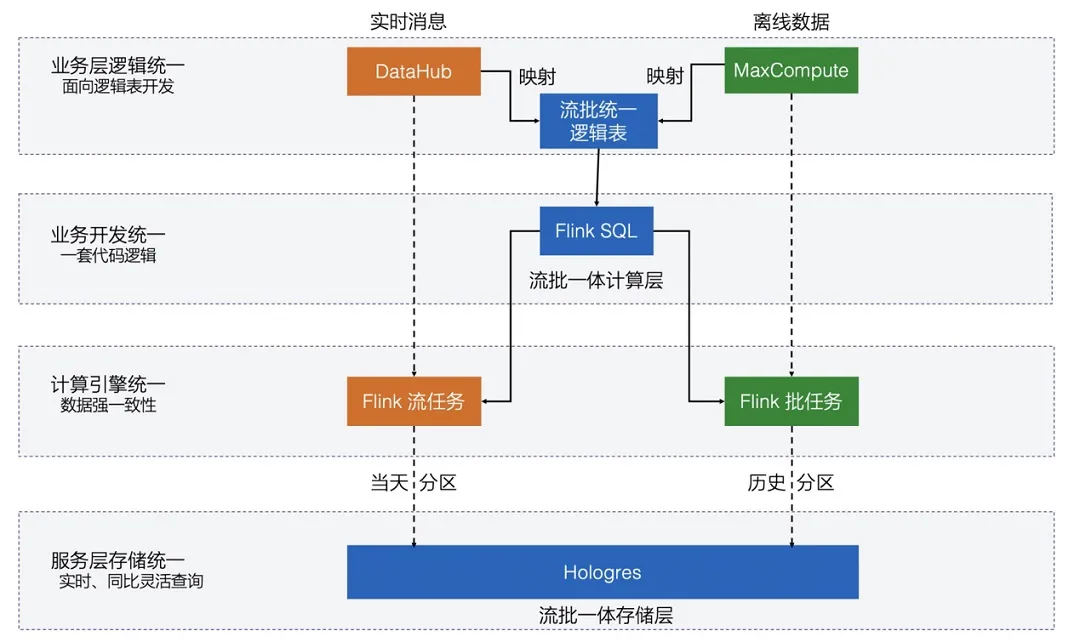
基于批和流的两种不同计算引擎产出,难解决的是数据逻辑和口径对齐问题,很难保证两套技术开发出的数据统计结果是一致的
资源方面 实时和离线资源问题,实时白天资源高峰期,晚上资源闲置,离线和实时混布自然的削峰填谷,节省资源开销
批流一体
批处理是流处理的特例。不过出于批处理场景的执行效率、资源需求和复杂度各方面的考虑,在 Flink 设计之初流处理应用和批处理应用尽管底层都是流处理,但在编程 API 上是分开的。这允许 Flink 在执行层面仍沿用批处理的优化技术,并简化掉架构移除掉不需要的 watermark、checkpoint 等特性(移除)。 开个microbatch
因为 Batch SQL 与 Streaming SQL 在大部分语法及语义上是一致的,不同点在于 Streaming SQL 另有拓展语法的来支持 Watermark、Time Characteristic 等流处理领域的特性,因此 SQL parser 是 Batch/Stream 共用的。关键点在于对于关系代数 RelNode 的翻译上。
为了实现完全的流批一体,Flink 社区准备在 DataStream 引入 BoundedStream 的概念来表示有界的数据流,完全从各种意义上代替 DataSet。
BoundedStream 将是 DataStream 的特例,同样使用 Transformation 和 StreamOperator,且同时需要继承 DataSet 的批处理优化。这些优化可以分为 Task 线程模式、调度策略及容错和计算模型及算法这几部分
Task 线程模型
每个 Task 同时只读取和处理一个 Split。
调度策略及容错
批处理作业和流处理作业在 Task 调度上是很不同的。批处理作业的多个 Task 并不需要同时在线,可以根据依赖关系先调度一批 Task,等它们结束后再运行另一批
相反地,流作业的所有 Task 需要在作业启动的时候就全部被调度,然后才可以开始处理数据。前一种调度策略通常称为懒调度(Lazy Scheduling),后一种通常称为激进调度(Eager Scheduling)。为了实现流批一体,Flink 需要在 StreamGraph 中同时支持这两种调度模式,也就是说新增懒调度
随调度而来的问题还有容错,这并不难理解,因为 Task 出现错误后需要重新调度来恢复。而懒调度的一大特点是,Task 计算的中间结果需要保存在某个高可用的存储中,然后下个 Task 启动后才能去获取。
Flink 并没有持久化中间结果。这就导致了如果该 TaskManager 崩溃,中间结果会丢失,整个作业需要从头读取数据或者从 checkpoint 来恢复。这对于实时流处理来说是很正常的,然而批处理作业并没有 checkpoint 这个概念,批处理通常依赖中间结果的持久化来减小需要重算的 Task 范围,因此 Flink 社区引入了可插拔的 Shuffle Service 来提供 Suffle 数据的持久化以支持细粒度的容错恢复,具体可见 FLIP-31[8]
计算模型及算法
与 Table API 相似,同一种计算在流处理和批处理中的算法可能是不同的。典型的一个例子是 Join: 它在流处理中表现为两个流的元素的持续关联,任何一方的有新的输入都需要跟另外一方的全部元素进行关联操作,也就是最基础的 Nested-Loop Join;而在批处理中,Flink 可以将它优化为 Hash Join,即先读取一方的全部数据构建 Hash Table,再读取另外一方进行和 Hash Table 进行关联
这种差异性本质是算子在数据集有界的情况下的优化。拓展来看,数据集是否有界是 Flink 在判断算子如何执行时的一种优化参数,这也印证了批处理是流处理的特例的理念。因此从编程接口上看,BoundedStream 作为 DataStream 的子类,基于输入的有界性可以提供如下优化:
- 提供只可以应用于有界数据流的算子,比如 sort。
- 对某些算子可以进行算法上的优化,比如 join。
此外,批处理还有个特点是不需要在计算时输出中间结果,只要在结束时输出最终结果,这很大程度上避免了处理多个中间结果的复杂性。因此,BoundedStream 还会支持非增量(non-incremental)执行模式。这主要会作用于与 Time Charateritic 相关的算子:
- Processing Time Timer 将被屏蔽。
- Watermark 的提取算法不再生效,Watermark 直接从开始时的 -∞ 跳到结束时的 +∞ (直接没有吧??)
https://flink.apache.org/news/2019/02/13/unified-batch-streaming-blink.html
Count Distinct
count(distinct item_id)
一个共享 DateState
JoinState
上游有UK,且JoinKey 包含UK (JK,ValueState
上游有UK,但JoinKey不包含UK (JK,MapState<UK,ROW>) 上游没有UK <JK,ListState
无JoinKey
批计算
容错 (Batch Shuffle mode)
资源模型 -提高资源利用率
Hive集成 -Meta/
SQL 优化 -丰富完善的Rules
SQL 支持 -Rules
Batch mode/pipeline mode
Batch mode
容错好,可以单点恢复 调度好,不管多少资源都可以运行 性能差,中间数据要落盘,强烈建议开启压缩
Pipeline Mode
容错差,只能全局重来
调度差,你得保证有足够的资源 性能好,Pipeline 执行,完全复用Stream,复用流控反压等功能
Session Mode
批排序算子
Normalized Key +多线程
最大值是16字节 是截取前面的16字节(不是整个key排序)
Write Thread SortThread SpillThread Merge Thread
默认用 Cost来选取是否两阶段
Join
HybridHashJoin VS SortMergeJoin
(内存不够 多余的 spill)
Batch已经达到 一个 production的 相比Hive 有7倍的性能
流作业需要全部调度起来
批作业
HashJoin
内部先构建Index
再消费一个数据
从Concurrent-Group的调度
Blocking的方式 网络的shuffle
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/10/27/Flink%E6%B5%81%E6%89%B9%E7%BB%9F%E4%B8%80/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)