数据湖
大数据架构的痛点
基于离线存储的Hive,其次是提供点查询能力的HBase、Cassandra、然后是MPP架构号称能面向HTAP的Greenplum、以及最新兴起的用于做快速分析的Clickhouse等等都是基于解决方案而面世的存储产品。 但以上的每个存储产品都是一个数据的孤岛,比如为了解决点查询的问题,数据需要在HBase里面存储一份;为了解决列存的快速分析,数据需要在Druid或者Clickhouse里面存一份;为了解决离线计算又需要在Hive里面存储一份,这样带来的问题就是:
1)冗余存储
数据将会存储在多个系统中,增加冗余存粗。
2)高维护成本
每个系统的数据格式不一致,数据需要做转换,增加维护成本,尤其是当业务到达一定量级时,维护成本剧增。
3)高学习成本
多个系统之前需要完全打通,不同的产品有不同的开发方式,尤其是针对新人来说,需要投入更多的精力去学习多种系统,增加学习成本。
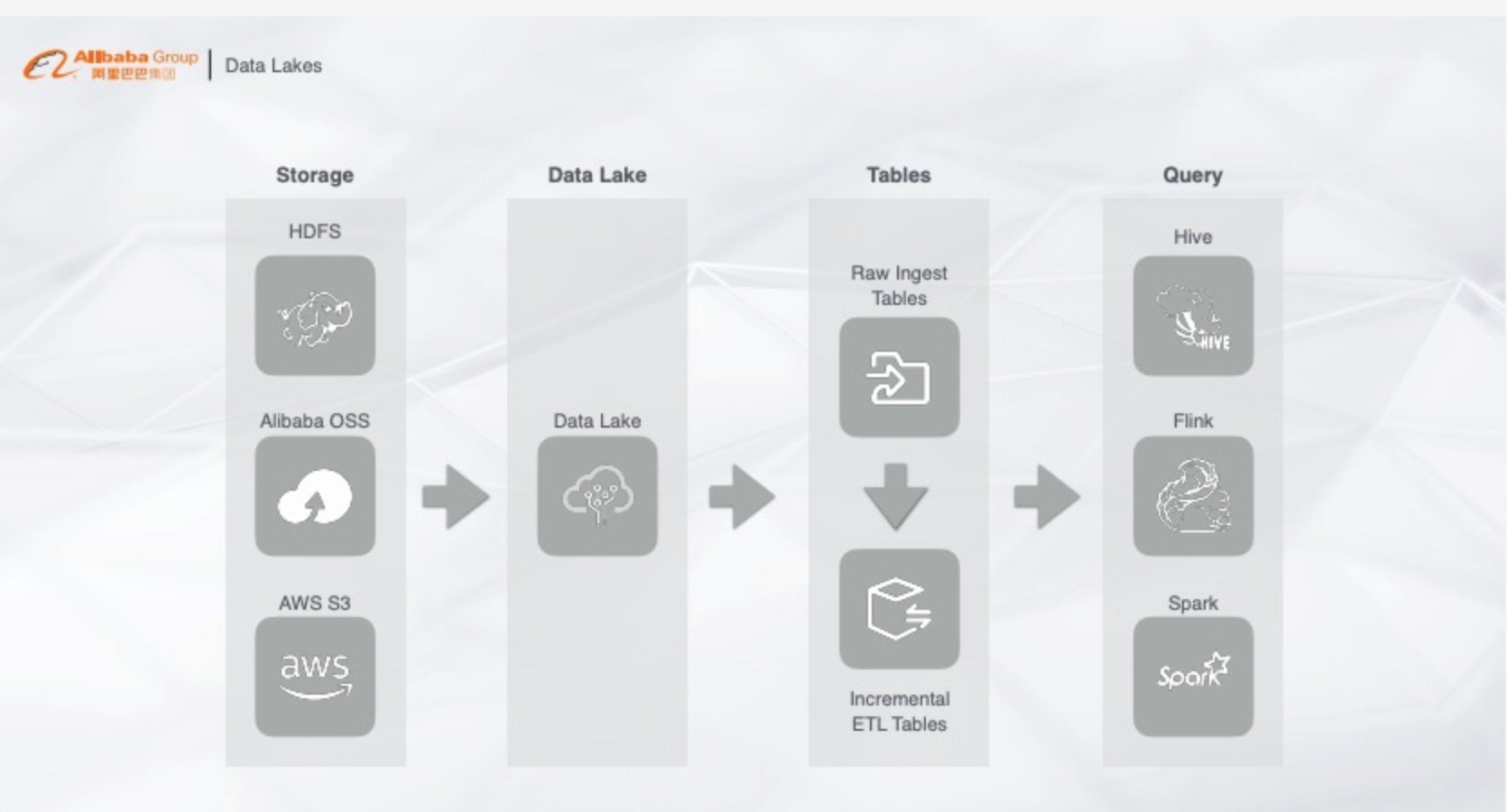
Kappa 架构
Kappa架构 Flink 即做流 又做批
首先采集的数据有统一的存储,不管是HDFS、OSS还是AWS,数据以增量的形式存储在数据湖里,再通过查询层不管是Hive、Spark还是Flink,根据业务需求选择一个产品来做查询,这样实时数据以及离线数据都能直接查询。整个架构看起来很美好,但是实际问题在于:
1)数据增量写入不满足实时性
开源的实时写入并不是实时写入,而是增量写入。实时和增量的区别在于,实时写一条数据就能立马查询可见,但是增量为了提高吞吐会将数据一批一批的写入。那么这套方案就不能完全满足数据实时性的要求。
Flink写 HDFS是 增量 写入,并且 用 OLAP查询 又会有计算 延迟情况
2)查询的QPS
我们希望这个架构既能做实时分析,又能做流计算的维表查询,存储里面的数据能否通过Flink做一个高并发的查询,例如每秒钟支持上千万上亿QPS的查询
Redis 和 HBASE 做 上千万的QPS 查询的话 需要 加 cache
3)查询的并发度
整个方案本质都是离线计算引擎,只能支持较低的并发,如果要支持每秒钟上千的并发,需要耗费大量的资源,增加成本。 综上所述,这个方案目前还不能完全解决问题,只能作为一个初期的解决方案。
数据湖架构
在最底层,通过阿里云对象存储OSS作为数据库存储, 大文件瞬时Rename、 加速缓存等都不是问题。OSS可以开放对接各类计算引擎,让上层的计算任务更加灵活,并且支持数据冷热全生命周期管理,打破数据孤岛。
在OSS的上面是数据库构建产品Data Lake Formation,它可以提供通用存储上的两个核心的功能。
第一是统一的数据加速服务,可以让OSS存储像本地一样高效。
第二是统一的元数据服务,所有上层的引擎都能够更加简单的理解、对接和了解数据的格式,方便多样化的上层分析计算和处理。
而数据存储的目的还是为了计算,第三层开源大数据计算引擎E-MapReduce可以给数据湖提供灵活、高效的大数据计算能力。
这样的体系结构,一方面为各种离线计算、流计算等提供了灵活底座,另一方面存储与计算架构实现了分离和容器化,让湖上的计算弹性和可扩展性更优秀。
传统的观念认为,数据仓库构建非常困难,但现在,建设数仓可以像买一套office 一样简单。
数据湖系统核心能力
元数据可拓展
流批一体
数据修改
数据质量
多层底层存储
多种引擎
ACID事务
数据湖系统的核心组件
1.构建于存储系统和文件格式之上的数据组织方式
2.保证ACID事务,及一定的并发能力
3.提供“行” 级别的数据修改,删除的能力
4.确保schema的准确性,提供“热”变更能力
数据仓库 VS 数据湖
数据仓库的成长性很好,而数据湖更灵活。数据仓库支持的数据结构种类比较单一,数据湖的种类比较丰富,可以包罗万象。数据仓库更加适合成熟的数据当中的分析和处理,数据湖更加适合在异构数据上的价值的挖掘。
湖仓一体的意义就是说我不需要看见湖和仓,数据有着打通的元数据的格式,它可以自由的流动,也可以对接上层多样化的计算生态
数据湖的技术对比
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/10/23/%E6%95%B0%E6%8D%AE%E6%B9%96/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)