Solr架构

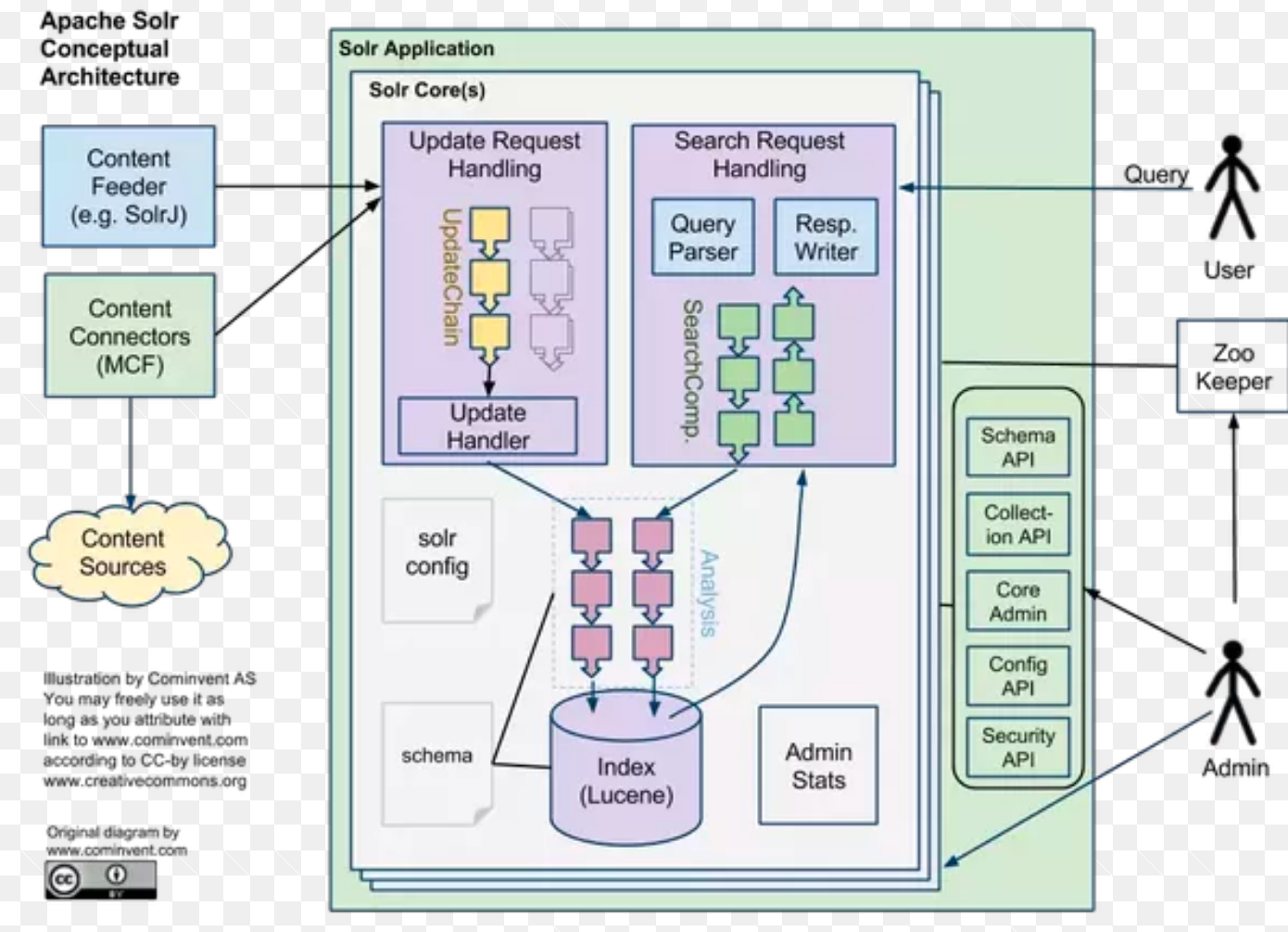
Solr基础内容
Solr Core
core是单一的索引数据,索引又是由多个Document组成的
Solr设计多Core来存放索引就是为了实现把两个不相干的对象进行分离独立管理,这样每个对象的索引都有自己的一套Schema.xml和 solrconfig.xml进行管理,彼此之间相互不影响。
Solr和数据库的差异:数据库有简单的基于通配符的文本模糊查询,但是会导致全表扫描,性能很差,而Solr是把搜索关键字保存在一个倒排表例,搜索性能提高了N个数量级,但Solr创建所有速度相对较慢,
Solr设计多Core主要为了
1.重建索引
2.配置变更影响最小化
3.索引合并和分裂
4.core热交换
Solr索引
Lucene索引原理
Lucene 建立索引的过程就是创建倒排索引表的过程,
Lucene索引结构
索引Index
文档Document
域Field
段Segment
词Term
Luence内部倒排索引表构建过程
想要根据关键词搜索到包含该关键词的文档
先对文档进行分词处理,对于英文文档,一般就是按照空格进行分词,对于中文而言,需要使用相应的中文分词器来处理.得到所有的单词后,还需要剔除一些毫无意义的单词,比如 at in to is ,这些是停用次,中文里面是 是 的,英文还有时态 比如 loved 需要还原成love
这样就能知道每个文档包含了哪些单词,即文档–>词的映射
而倒排索引是 词->文档的映射,即反向信息。
当用户根据词进行搜索时,会返回多个文档给用户,这就涉及到 多个文档的排列顺序,希望把用户搜索关键词相关的文档优先排在前面展示给用户,还需要每个单词在文档中的出现频率即Term Frequency,要进行高亮展示的话,还需要知道 Term Position
我们将得到如下一个倒排索引结构:
Make->0,1,[5,9] 2,1,[8,11]
0,1,[5,9] 依次表示文档的id,词的频率,词出现的位置等
如果你想存储一些额外的自定义信息来影响排序,可以用 payload功能
比如
Book -> 0,1,[13,16],[0.9], 2,1,[18,19],[0.1]
0.9和 0.1是词性的分数,比如是 形容词 动词等
倒排表构建完成之后,Lucene首先根据用户输入的单词对 Term dictionary词典进行二元查找,找到该Term,通过词频文件指针可以读取到该Term对应的文档ID,从而找到该搜索词在哪些文档中出现过,最终将结果返回给用户.返回给用户之前还涉及文档的打分阶段
Lucene的评分机制
内部的打分机制通过Query,Weight,Scorer,Similarity这几个协作完成的
queryNorm(q):用来计算每个查询的权重,使得每个query之间可以比较,会影响document的得分值但是不影响排序,因为每个Document都会应用这个值,对于同一个query来说是 恒值
1/sumOfSquaredWeights^2
Score = 查询项Query出现的频率(query,Document) * queryNorm(q)* 查询项里面每个Term的加权
查询项里面每个Term的加权 : 单个Term计算方法
Tf(t,d) * idf(t)^2*T.getBoot *norm(t,d)
Tf(t,d):用来统计指定的Term在Document中出现的频率,出现次数越多得分越高
Idf(t):统计出现 term的document的频率 docFreq,docFreq越小,idf越大, 物以稀为贵的意思
t.getBoot:给 Term设置的权重值,比如 term是 java,可以表达成 java^1.2
Norm(t,d):term的boot,token个数越多,匹配度越低,好比 你在 10000个字符中匹配到一个关键词和10个字符中匹配到一个关键词,后者的权重更大应该排在前面
Solr分词
分词的基本介绍
分词器
中文分词器
Solr查询
solr查询相关度
Solr排序
Solr Facet
Solr Group分组
group的分页与排序
Solr 高级查询
深度分页
自定义排序
solr相关性评分
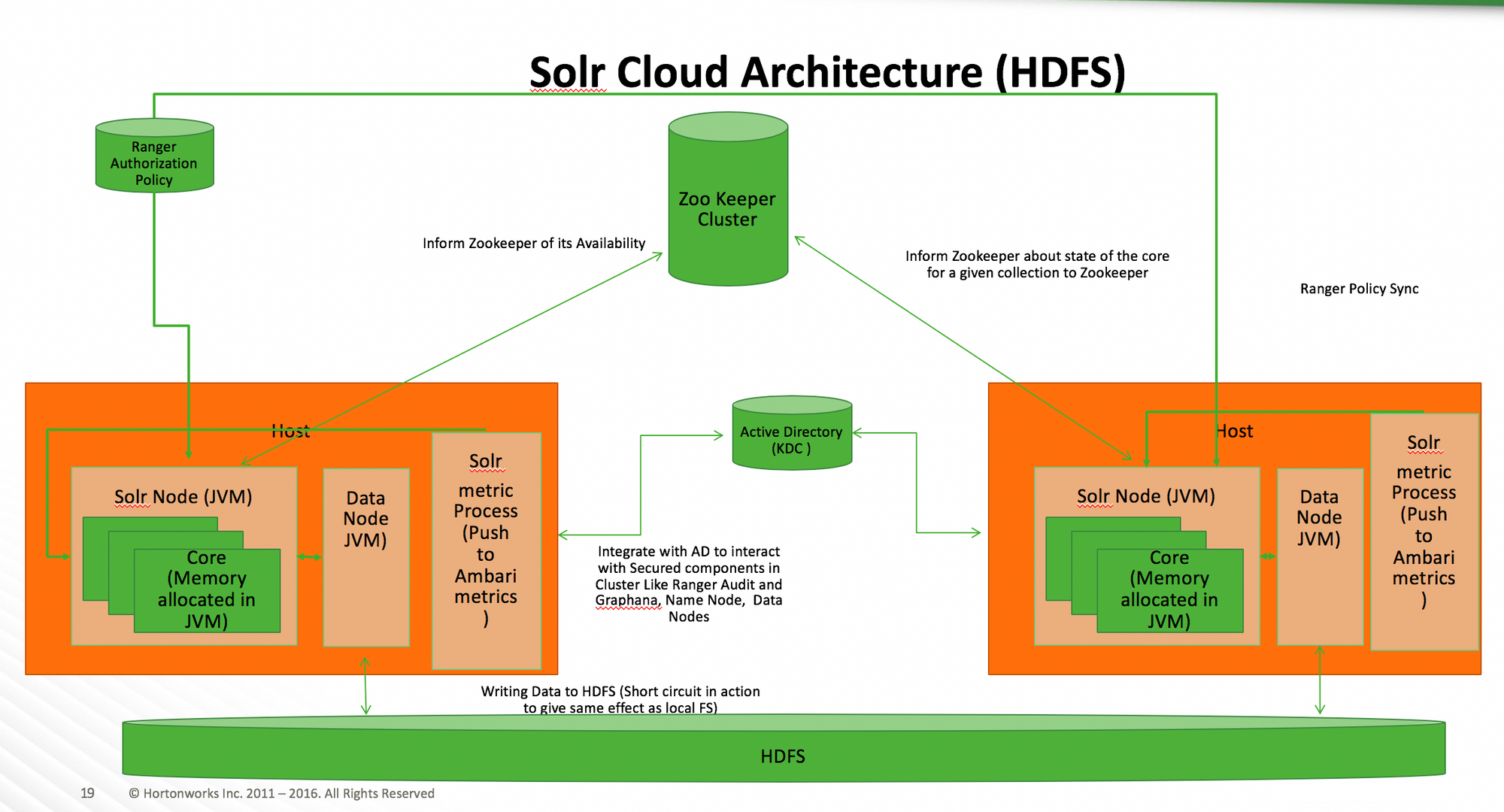
SolrCloud
Solr vs Elasticsearch
它们都是围绕核心底层搜索库Lucene构建的,但是它们在功能(例如可伸缩性,易于部署以及社区存在等)方面有所不同。在静态数据方面,Solr具有更多优势,这是因为它具有高速缓存,并且能够使用未反转的阅读器进行构面和排序(例如电子商务)。另一方面,Elasticsearch更适合-并且更经常使用-时间序列数据用例,例如日志分析用例。
Solr vs. Elasticsearch引擎性能和可伸缩性基准**
在性能方面,Solr和Elasticsearch大致相同。我们之所以说“大致”,是因为没有人做过良好,全面和公正的基准测试。对于95%的用例,就性能而言,这两种选择都是不错的选择,剩下的5%需要用其特定的数据和特定的访问模式来测试这两种解决方案。
就是说,如果您的数据大部分为静态数据,并且需要全精度的数据分析和超快的性能,则应该考虑Solr。
年龄,成熟度和搜索趋势
在2010年左右,Elasticsearch成为市场上的另一种选择。那时,它远没有Solr稳定,没有Solr的功能深度,没有思想份额,品牌等等。但是它还有其他一些优点:Elasticsearch尚处于起步阶段,它基于更现代的原理,针对更现代的用例,并且旨在简化大索引和高查询率的处理。
Elasticsearch不再是新事物,但它仍然是闪亮的。它缩小了Solr的功能差距,在某些情况下甚至超过了。当然,它周围还有更多嗡嗡声。至此,两个项目都非常成熟。两者都有很多功能。两者都是稳定的。但是,我们不得不说,我们确实看到了更多有问题的Elasticsearch集群,但是我们认为这主要是由于以下几个原因:
- 传统上,Elasticsearch较容易上手,它使任何人都可以开箱即用地使用它,而无需过多地了解其工作原理。上手很棒,但是当数据/集群增长时很危险。
- Elasticsearch易于扩展,吸引了一些用例,这些用例需要具有更多数据和更多节点的更大集群。
- Elasticsearch更具动态性–数据可以随节点的移动而轻松地在集群中移动,这会影响集群的稳定性和性能。
- 传统上,Solr更侧重于文本搜索,而Elasticsearch的目标也是处理分析类型的查询,而这种查询是有代价的。
缓存
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/10/01/Solr%E5%9F%BA%E7%A1%80%E4%BB%8B%E7%BB%8D/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)