分布式系统的三个特征
Consistency
一致性,是指所有节点在同一时刻的数据是相同的,即更新操作执行结束并响应用户完成后,所有节点存储的数据会保持相同
也就是集群中节点之间通过复制技术保证每个节点上的数据在同一时刻是相同的
Availability
可用性,是指系统提供的服务一直处于可用状态,对于用户的请求可即时响应。
Partition Tolerance
分区容错性,是指在分布式系统遇到网络分区的情况下,仍然可以响应用户的请求。网络分区是指因为网络故障导致网络不连通,不同节点分布在不同的子网络中,各个子网络内网络正常
CAP理论
在分布式系统中 C、A、P 这三个特征不能同时满足,只能满足其中两个
保 CA 弃 P
在分布式系统中,现在的网络基础设施无法做到始终保持稳定,网络分区(网络不连通)难以避免。牺牲分区容错性 P,就相当于放弃使用分布式系统。因此,在分布式系统中,这种策略不需要过多讨论。既然分布式系统不能采用这种策略,那单点系统毫无疑问就需要满足 CA 特性了。比如关系型数据库 DBMS(比如 MySQL、Oracle)部署在单台机器上,因为不存在网络通信问题,所以保证 CA 就可以了。
保 CP 弃 A
一个分布式场景需要很强的数据一致性,或者该场景可以容忍系统长时间无响应的情况下,保 CP 弃 A 这个策略就比较适合。
一个保证 CP 而舍弃 A 的分布式系统,一旦发生网络分区会导致数据无法同步情况,就要牺牲系统的可用性,降低用户体验,直到节点数据达到一致后再响应用户。
这种策略通常用在涉及金钱交易的分布式场景下,因为它任何时候都不允许出现数据不一致的情况,否则就会给用户造成损失。因此,这种场景下必须保证 CP。保证 CP 的系统有很多,典型的有 Redis、HBase、ZooKeeper 等。
保 AP 弃 C
如果一个分布式场景需要很高的可用性,或者说在网络状况不太好的情况下,该场景允许数据暂时不一致,那这种情况下就可以牺牲一定的一致性了。网络分区出现后,各个节点之间数据无法马上同步,为了保证高可用,分布式系统需要即刻响应用户的请求。但,此时可能某些节点还没有拿到最新数据,只能将本地旧的数据返回给用户,从而导致数据不一致的情况
适合保证 AP 放弃 C 的场景有很多。比如,很多查询网站、电商系统中的商品查询等,用户体验非常重要,所以大多会保证系统的可用性,而牺牲一定的数据一致性。
分布式数据存储系统
分布式存储系统的核心逻辑,就是将用户需要存储的数据根据某种规则存储到不同的机器上,当用户想要获取指定数据时,再按照规则到存储数据的机器里获取
数据的特征
结构化数据
通常是指关系模型数据,其特征是数据关联较大、格式固定。火车票信息比如起点站、终点站、车次、票价等,就是一种结构化数据。结构化数据具有格式固定的特征,因此一般采用分布式关系数据库进行存储和查询。
半结构化数据
通常是指非关系模型的,有基本固定结构模式的数据,其特征是数据之间关系比较简单。比如 HTML 文档,使用标签书写内容。半结构化数据大多可以采用键值对形式来表示,比如 HTML 文档可以将标签设置为 key,标签对应的内容可以设置为 value,因此一般采用分布式键值系统进行存储和使用。
非结构化数据
是指没有固定模式的数据,其特征是数据之间关联不大。比如文本数据就是一种非结构化数据。这种数据可以存储到文档中,通过 ElasticSearch(一个分布式全文搜索引擎)等进行检索
数据分布设计原则
数据均匀
1.不同存储节点中存储的数据要尽量均衡,避免让某一个或某几个节点存储压力过大,而其他节点却几乎没什么数据。比如,现在有 100G 数据,4 个同类型节点,通常希望数据存储时尽可能均衡,比如每个节点存储 25G 数据。
2.用户访问也要做到均衡,避免出现某一个或某几个节点的访问量很大,但其他节点却无人问津的情况。比如,现在有 1000 个请求,对于上述存储数据的 4 个节点,处理用户访问请求尽量均衡,比如每个节点处理 250 个请求,当然这是非常理想的情况,实际情况下,每个节点之间相差不太大即可。
数据稳定
当存储节点出现故障需要移除或者扩增时,数据按照分布规则得到的结果应该尽量保持稳定,不要出现大范围的数据迁移。比如,现有 100G 数据,刚开始有 4 个同类型节点(节点 1~4),每个节点存储 25G 数据,现在节点 2 故障了,也就是说每个节点需要存储 100G/3 数据。数据稳定,就是尽可能只迁移节点 2 上的数据到其他节点上,而不需要对大范围或所有数据进行迁移存储。当然,如果有扩展同类型节点,也是尽可能小范围迁移数据到扩展的节点上
节点异构性
不同存储节点的硬件配置可能差别很大。比如,有的节点硬件配置很高,可以存储大量数据,也可以承受更多的请求;但,有的节点硬件配置就不怎么样,存储的数据量不能过多,用户访问也不能过多。如果这种差别很大的节点,分到的数据量、用户访问量都差不多,本质就是一种不均衡。所以,一个好的数据分布算法应该考虑节点异构性
隔离故障域
是为了保证数据的可用和可靠性。比如,我们通常通过备份来实现数据的可靠性。但如果每个数据及它的备份,被分布到了同一块硬盘或节点上,就有点违背备份的初衷了。所以,一个好的数据分布算法,应该为每个数据映射一组存储节点,这些节点应该尽量在不同的故障域,比如不同机房、不同机架等
性能稳定性
数据存储和查询的效率要有保证,不能因为节点的添加或者移除,造成存储或访问性能的严重下降
数据分布方法
一致性哈希
一致性哈希是指将存储节点和数据都映射到一个首尾相连的哈希环上,存储节点可以根据 IP 地址进行哈希,数据通常通过顺时针方向寻找的方式,来确定自己所属的存储节点,即从数据映射在环上的位置开始,顺时针方向找到的第一个存储节点
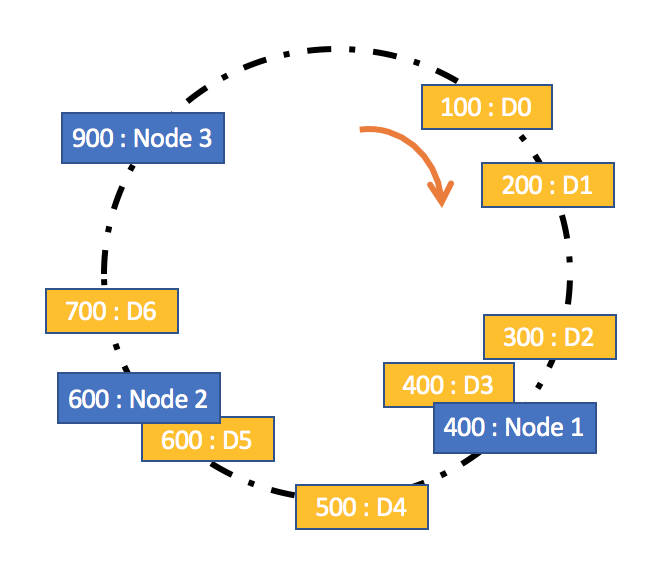
一致性哈希是对哈希方法的改进,在数据存储时采用哈希方式确定存储位置的基础上,又增加了一层哈希,也就是在数据存储前,对存储节点预先进行了哈希。这种改进可以很好地解决哈希方法存在的稳定性问题。当节点加入或退出时,仅影响该节点在哈希环上顺时针相邻的后继节点。比如,当 Node2 发生故障需要移除时,由于 Node3 是 Node2 顺时针方向的后继节点,本应存储到 Node2 的数据就会存储到 Node3 中,其他节点不会受到影响,因此不会发生大规模的数据迁移。
一致性哈希方法虽然提升了稳定性,但随之而来的均匀性问题也比较明显,即对后继节点的负载会变大。有节点退出后,该节点的后继节点需要承担该节点的所有负载,如果后继节点承受不住,便会出现节点故障,导致后继节点的后继节点也面临同样的问题。
带有限负载的一致性哈希
不是很好的算法,增加了 寻址复杂度,就不写了
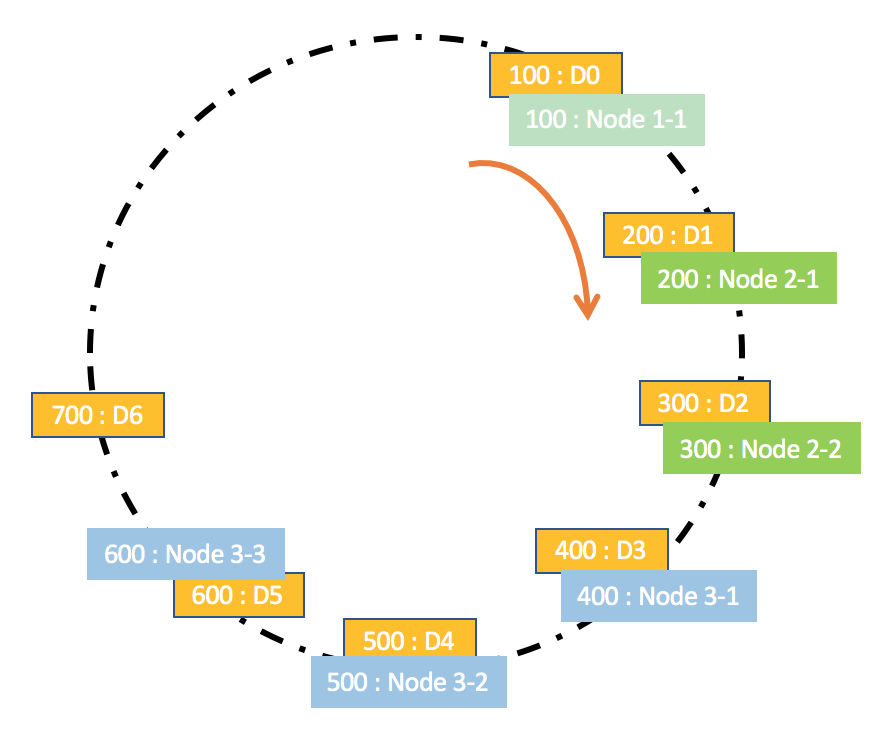
带虚拟节点的一致性哈希
带虚拟节点的一致性哈希方法,核心思想是根据每个节点的性能,为每个节点划分不同数量的虚拟节点,并将这些虚拟节点映射到哈希环中,然后再按照一致性哈希算法进行数据映射和存储。
这种方法不仅解决了节点异构性问题,还提高了系统的稳定性。
当节点变化时,会有多个节点共同分担系统的变化,因此稳定性更高。
比如,当某个节点被移除时,对应该节点的多个虚拟节点均会移除,而这些虚拟节点按顺时针方向的下一个虚拟节点,可能会对应不同的物理节点,即这些不同的物理节点共同分担了节点变化导致的压力。
当然,这种方法引入了虚拟节点,增加了节点规模,从而增加了节点的维护和管理的复杂度,比如新增一个节点或一个节点故障时,对应到虚拟节点构建的哈希环上需要新增和删除多个节点,数据的迁移等操作相应地也会很复杂
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/09/25/%E5%88%86%E5%B8%83%E5%BC%8F%E6%95%B0%E6%8D%AE%E5%AD%98%E5%82%A8/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)