解决资源与请求者的匹配问题
单体调度,双层调度,共享调度
任务存在优先级,那当我们需要执行多个任务的时候,通常需要满足优先级高的任务优先执行的条件。但在这些条件中,服务器资源能够满足用户任务对资源的诉求是必须的。而为用户任务寻找合适的服务器这个过程,在分布式领域中叫作调度。在分布式系统架构中,调度器就是一个非常重要的组件。它通常会提供多种调度策略,负责完成具体的调度工作。
单体调度
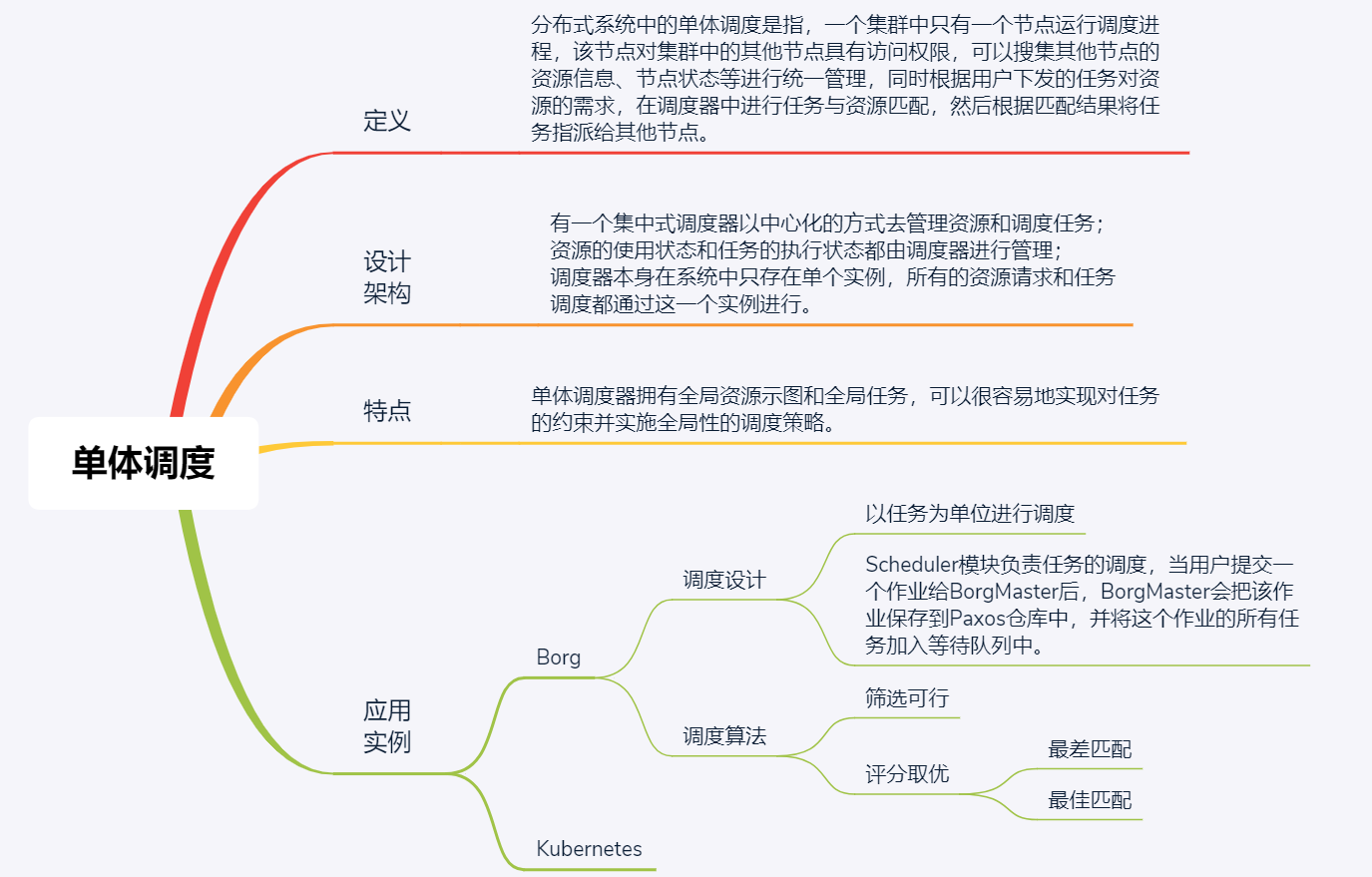
分布式系统中的单体调度是指,一个集群中只有一个节点运行调度进程,该节点对集群中的其他节点具有访问权限,可以搜集其他节点的资源信息、节点状态等进行统一管理,同时根据用户下发的任务对资源的需求,在调度器中进行任务与资源匹配,然后根据匹配结果将任务指派给其他节点。
调度算法的核心思想是“筛选可行,评分取优”,
具体包括两个阶段:
1.可行性检查,找到一组可以运行任务的机器(Borglet);
2.评分,从可行的机器中选择一个合适的机器(Borglet)。
在可行性检查阶段,调度器会找到一组满足任务约束,且有足够可用资源的机器。比如,现在有一个任务 A 要求能部署的节点是节点 1、节点 3 和节点 5,并且任务资源需求为 0.5 个 CPU、2MB 内存。根据任务 A 的约束条件,可以先筛选出节点 1、节点 3 和节点 5,然后根据任务 A 的资源需求,再从这 3 个节点中寻找满足任务资源需求的节点。
其中,常见的评分算法,包括“最差匹配”和“最佳匹配”两种。
早期使用修改过的 E-PVM 算法来评分,该算法的核心是将任务尽量分散到不同的机器上。该算法的问题在于,它会导致每个机器都有少量的无法使用的剩余资源,因此有时称其为“最差匹配”(worst fit)。
比如,现在有两个机器,机器 A 的空闲资源为 1 个 CPU 和 1G 内存、机器 B 的空闲资源为 0.8 个 CPU 和 1.2G 内存;同时有两个任务,Task1 的资源需求为 0.4 个 CPU 和 0.3G 内存、Task2 的资源需求为 0.3CPU 和 0.5G 内存。按照最差匹配算法思想,Task1 和 Task2 会分别分配到机器 A 和机器 B 上,导致机器 A 和机器 B 都存在一些资源碎片,可能无法再运行其他 Task。
与之相反的是“最佳匹配”(best fit),即把机器上的任务塞得越满越好。这样就可以“空”出一些没有用户作业的机器(它们仍运行存储服务),来直接放置大型任务。
比如,在上面的例子中,按照最佳匹配算法的思想,Task1 和 Task2 会被一起部署到机器 A 或机器 B 上,这样未被部署的机器就可以用于执行其他大型任务了。但是,如果用户或 Borg 错误估计了资源需求,紧凑的装箱操作会对性能造成巨大的影响。比如,用户估计它的任务 A 需要 0.5 个 CPU 和 1G 内存,运行该任务的服务器上由于部署了其他任务,现在还剩 0.2 个 CPU 和 1.5G 内存,但用户的任务 A 突发峰值时(比如电商抢购),需要 1 个 CPU 和 3G 内存,很明显,初始资源估计错误,此时服务器资源不满足峰值需求,导致任务 A 不能正常运行。
所以说,最佳匹配策略不利于有突发负载的应用,而且对申请少量 CPU 的批处理作业也不友好,因为这些作业申请少量 CPU 本来就是为了更快速地被调度执行,并可以使用碎片资源。还有一个问题,这种策略有点类似“把所有鸡蛋放到一个篮子里面”,当这台服务器故障后,运行在这台服务器上的作业都会故障,对业务造成较大的影响。因此,这两个评分算法各有利弊。在实践过程中,我们往往会根据实际情况来选择更适宜的评分算法。比如,对于资源比较紧缺,且业务流量比较规律,基本不会出现突发情况的场景,可以选择最佳匹配算法;如果资源比较丰富,且业务流量会经常出现突发情况的场景,
两层调度
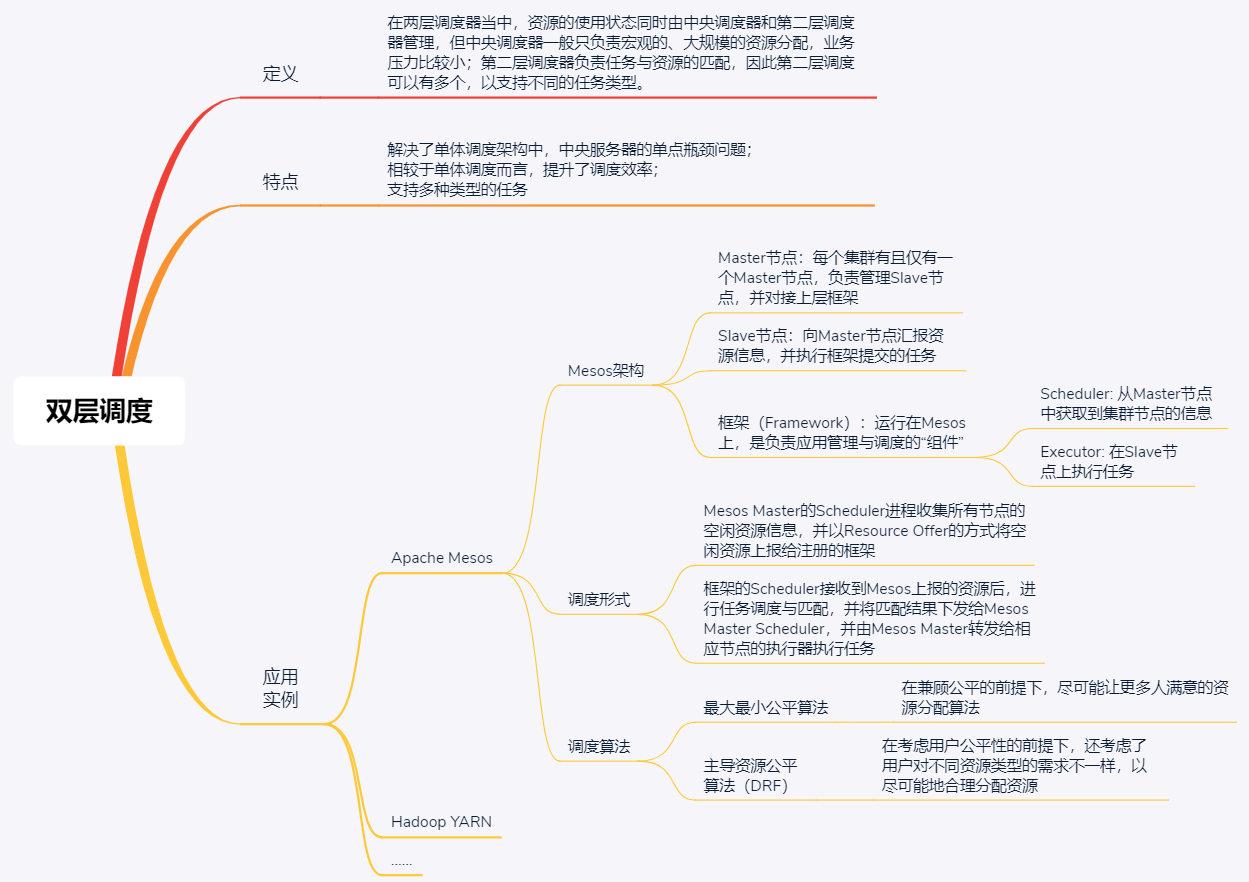
这是因为不同的服务具有不同的特征,对调度框架和计算的要求都不一样。比如说,你的业务最开始时只有批处理任务,后来发展到同时还包括流数据任务,但批处理任务是处理静态数据,流数据任务却是处理实时数据。显然,单体调度框架会随着任务类型增加而变得越来越复杂,最终出现扩展瓶颈。那么,为了提升调度效率并支持多种类型的任务,最直接的一个想法就是,能不能把资源和任务分开调度,也就是说一层调度器只负责资源管理和分配,另外一层调度器负责任务与资源的匹配呢。
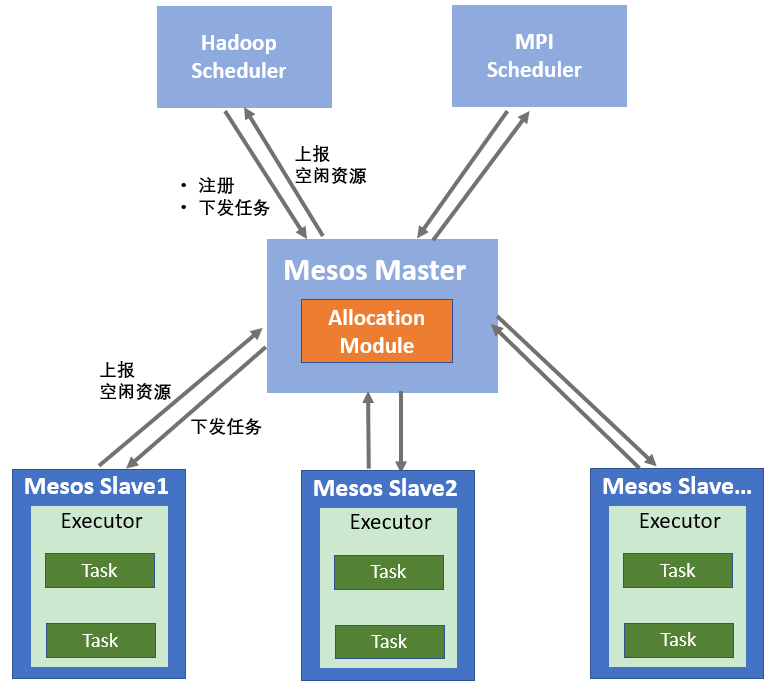
以 Mesos 为基础的分布式资源管理与调度框架包括两部分,即 Mesos 资源管理集群和框架。
资源管理集群是由一个 Master 节点和多个 Slave 节点组成的集中式系统。每个集群有且仅有一个 Master 节点,负责管理 Slave 节点,并对接上层框架;Slave 节点向 Master 节点周期汇报资源状态信息,并执行框架提交的任务。
框架(Framework)运行在 Mesos 上,是负责应用管理与调度的“组件”,比如 Hadoop、Spark、MPI 和 Marathon 等,不同的框架用于完成不同的任务,比如批处理任务、实时分析任务等。框架主要由调度器(Scheduler)和执行器(Executor)组成,调度器可以从 Master 节点获取集群节点的信息 ,执行器在 Slave 节点上执行任务
共享状态调度
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/09/21/%E5%88%86%E5%B8%83%E5%BC%8F%E8%B0%83%E5%BA%A6/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)