翻译 https://github.com/facebook/rocksdb/wiki
中文blog https://rocksdb.org.cn/doc/Leveled-Compaction.html
RocksDB
介绍
RocksDB最初在Facebook上是一种存储引擎,用于处理各种存储介质上的服务器工作负载,最初侧重于快速存储(尤其是闪存)。它是一个C ++库,用于存储键和值,它们是任意大小的字节流。它支持点查找和范围扫描,并提供不同类型的ACID保证。
在可定制性和自适应性之间取得平衡。RocksDB具有高度灵活的配置设置,可以将其设置为在各种生产环境中运行,包括SSD,硬盘,ramfs或远程存储。它支持各种压缩算法以及用于生产支持和调试的良好工具。另一方面,还努力限制旋钮的数量,提供足够好的开箱即用性能,并在适用的情况下使用一些自适应算法。
RocksDB借鉴了开源leveldb项目中的重要代码以及Apache HBase的构想。初始代码来自开源leveldb 1.5。它还基于RocksDB之前在Facebook上开发的代码和想法。
##
设计目标和特征
- 专为希望在本地或远程存储系统上存储多达TB数据的应用服务器而设计。
- 优化用于在快速存储中存储中小型键值-闪存设备或内存中
- 它在具有多个内核的处理器上运行良好
性能
RocksDB的主要设计要点是对于快速存储和服务器工作负载应具有高性能。它应该支持有效的点查找以及范围扫描。它应该是可配置的,以支持高随机读取工作量,高更新工作量或两者兼而有之。它的体系结构应支持轻松调整针对不同工作负载和硬件的折衷方案。
生产支持
RocksDB的设计方式应使其内置对工具和实用程序的支持,以帮助在生产环境中进行部署和调试。如果存储引擎仍无法自动适应应用程序和硬件,我们将提供一些参数以允许用户调整性能。
兼容性
此软件的较新版本应向后兼容,以便在升级到RocksDB的较新版本时,无需更改现有应用程序。除非使用新提供的功能,否则现有应用程序还应该能够还原到最新的旧版本。请参见不同版本之间的RocksDB兼容性。
架构
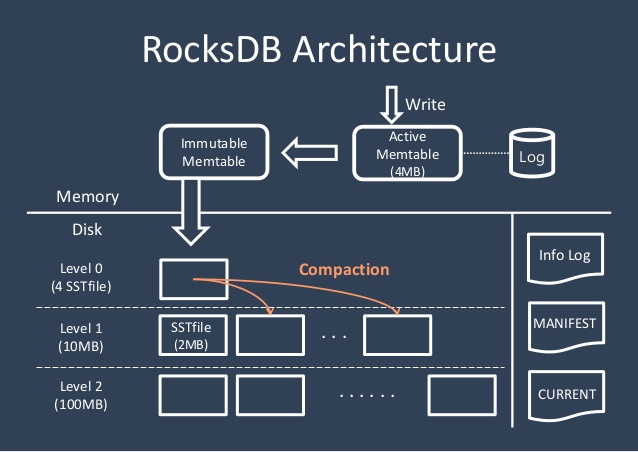
RocksDB是键值存储接口的存储引擎库,其中键和值是任意字节流。RocksDB组织所有数据的排序顺序和常用操作Get(key),NewIterator(),Put(key, val),Delete(key),和SingleDelete(key)。
RocksDB的三个基本构造是memtable,sstfile和logfile。
memTable是一个存储器内数据结构-新的写入被插入的memTable和任选地写入到日志文件。该日志文件是存储顺序排列的书面文件。当memTable中填满,它被刷新到一个sstfile存储和相应的日志文件可以安全地删除。sstfile中的数据已排序,以方便轻松查找键。
默认sstfile的格式如下
<beginning_of_file>
[data block 1]
[data block 2]
...
[data block N]
[meta block 1: filter block] (see section: "filter" Meta Block)
[meta block 2: index block]
[meta block 3: compression dictionary block] (see section: "compression dictionary" Meta Block)
[meta block 4: range deletion block] (see section: "range deletion" Meta Block)
[meta block 5: stats block] (see section: "properties" Meta Block)
...
[meta block K: future extended block] (we may add more meta blocks in the future)
[metaindex block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
<end_of_file>
细节 https://github.com/facebook/rocksdb/wiki/Rocksdb-BlockBasedTable-Format

RocksDB基础介绍
https://github.com/facebook/rocksdb/wiki/RocksDB-Basics
Leveled Compaction
https://rocksdb.org.cn/doc/Leveled-Compaction.html
Block Cache
相比LevelDB引入的新的特性
性能
- 多线程压缩
- 多线程内存插入
- 减少数据库互斥量保持
- 优化的基于级别的压实样式和通用压实样式
- 前缀Bloom过滤器
- 记忆布隆过滤器
- 单绽放过滤器覆盖整个SST文件
- 写锁优化
- 改进的Iter :: Prev()性能
- 在SkipList搜索过程中较少的比较器调用
- 使用大页面分配可分配内存。
特征
- 列族
- 事务和WriteBatchWithIndex
- 备份和检查点
- 合并运算符
- 压实过滤器
- RocksDB Java
- 手动压实与自动压实并行运行
- 永久缓存
- 散装
- 正向迭代器/尾部迭代器
- 一次删除
- 删除范围内的文件
- 引脚迭代器键/值
替代数据结构和格式
- 纯表格式(仅用于内存)
- 基于向量和基于哈希的内存表格式
- 基于时钟的缓存(即将推出)
- 可插拔信息日志
- 使用Blob注释事务日志写入(用于复制)
可调整性
- 限速
- 可调减速和停止阈值
- 选择保持所有文件打开
- 选择将所有索引和Bloom过滤器块保留在块缓存中
- 多种WAL恢复模式
- Fadvise提示以进行预读并避免在OS页面缓存中进行缓存
- 固定内存中L0文件的索引和Bloom筛选器的选项
- 更多压缩类型:zlib,lz4,zstd
- 压缩字典
- 校验和类型:xxhash
- 每个级别使用不同的级别大小乘数和压缩类型。
可管理性
- 统计
- 线程局部分析
- 命令行工具中的更多命令
- 用户定义的表属性
- 事件监听器
- 更多数据库属性
- 动态选项变更
- 从字符串或映射中获取选项
- 永久性选项文件
ROCKSDB的调优参数
读放大,写放大,和空间放大
RocksDB 和 LevelDB 通过后台的 compaction 来减少读放大(减少 SST 文件数量)和空间放大(清理过期数据),但也因此带来了写放大(Write Amplification)的问题。
- 写放大。实际写入 HDD/SSD 的数据大小和程序要求写入数据大小之比。正常情况下,HDD/SSD 观察到的写入数据多于上层程序写入的数据
在这三个因子里面取得平衡
MemTable
write_buffer_size | state.backend.rocksdb.writebuffer.size 单个 memtable 的大小,默认是64MB。当 memtable 大小达到此阈值时,就会被标记为不可变。一般来讲,适当增大这个参数可以减小写放大带来的影响,但同时会增大 flush 后 L0、L1 层的压力,所以还需要配合修改 compaction 参数,后面再提。
max_write_buffer_number | state.backend.rocksdb.writebuffer.count memtable 的最大数量(包含活跃的和不可变的),默认是2。当全部 memtable 都写满但是 flush 速度较慢时,就会造成写停顿,所以如果内存充足或者使用的是机械硬盘,建议适当调大这个参数,如4。
min_write_buffer_number_to_merge | state.backend.rocksdb.writebuffer.number-to-merge 在 flush 发生之前被合并的 memtable 最小数量,默认是1。举个例子,如果此参数设为2,那么当有至少两个不可变 memtable 时,才有可能触发 flush(亦即如果只有一个不可变 memtable,就会等待)。调大这个值的好处是可以使更多的更改在 flush 前就被合并,降低写放大,但同时又可能增加读放大,因为读取数据时要检查的 memtable 变多了。经测试,该参数设为2或3相对较好。
Block/Block Cache
block 是 sstable 的基本存储单位。block cache 则扮演读缓存的角色,采用 LRU 算法存储最近使用的 block,对读性能有较大的影响。
block_size | state.backend.rocksdb.block.blocksize block 的大小,默认值为4KB。在生产环境中总是会适当调大一些,一般32KB比较合适,对于机械硬盘可以再增大到128~256KB,充分利用其顺序读取能力。但是需要注意,如果 block 大小增大而 block cache 大小不变,那么缓存的 block 数量会减少,无形中会增加读放大。
block_cache_size | state.backend.rocksdb.block.cache-size block cache 的大小,默认为8MB。由上文所述的读写流程可知,较大的 block cache 可以有效避免热数据的读请求落到 sstable 上,所以若内存余量充足,建议设置到128MB甚至256MB,读性能会有非常明显的提升。
Compaction
target_file_size_base | state.backend.rocksdb.compaction.level.target-file-size-base L1层单个 sstable 文件的大小阈值,默认值为64MB。每向上提升一级,阈值会乘以因子 target_file_size_multiplier(但默认为1,即每级sstable最大都是相同的)。显然,增大此值可以降低 compaction 的频率,减少写放大,但是也会造成旧数据无法及时清理,从而增加读放大。此参数不太容易调整,一般不建议设为256MB以上。
max_bytes_for_level_base | state.backend.rocksdb.compaction.level.max-size-level-base L1层的数据总大小阈值,默认值为256MB。每向上提升一级,阈值会乘以因子 max_bytes_for_level_multiplier(默认值为10)。由于上层的大小阈值都是以它为基础推算出来的,所以要小心调整。建议设为 target_file_size_base 的倍数,且不能太小,例如5~10倍。
level_compaction_dynamic_level_bytes | state.backend.rocksdb.compaction.level.use-dynamic-size 这个参数之前讲过。当开启之后,上述阈值的乘法因子会变成除法因子,能够动态调整每层的数据量阈值,使得较多的数据可以落在最高一层,能够减少空间放大,整个 LSM Tree 的结构也会更稳定。对于机械硬盘的环境,强烈建议开启
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/09/20/RocksDB/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)