解决资源的分布式和异构性问题
CPU,内存,GPU,网络等物理资源虚拟化,形成逻辑资源池以便统一管理
如 k8s
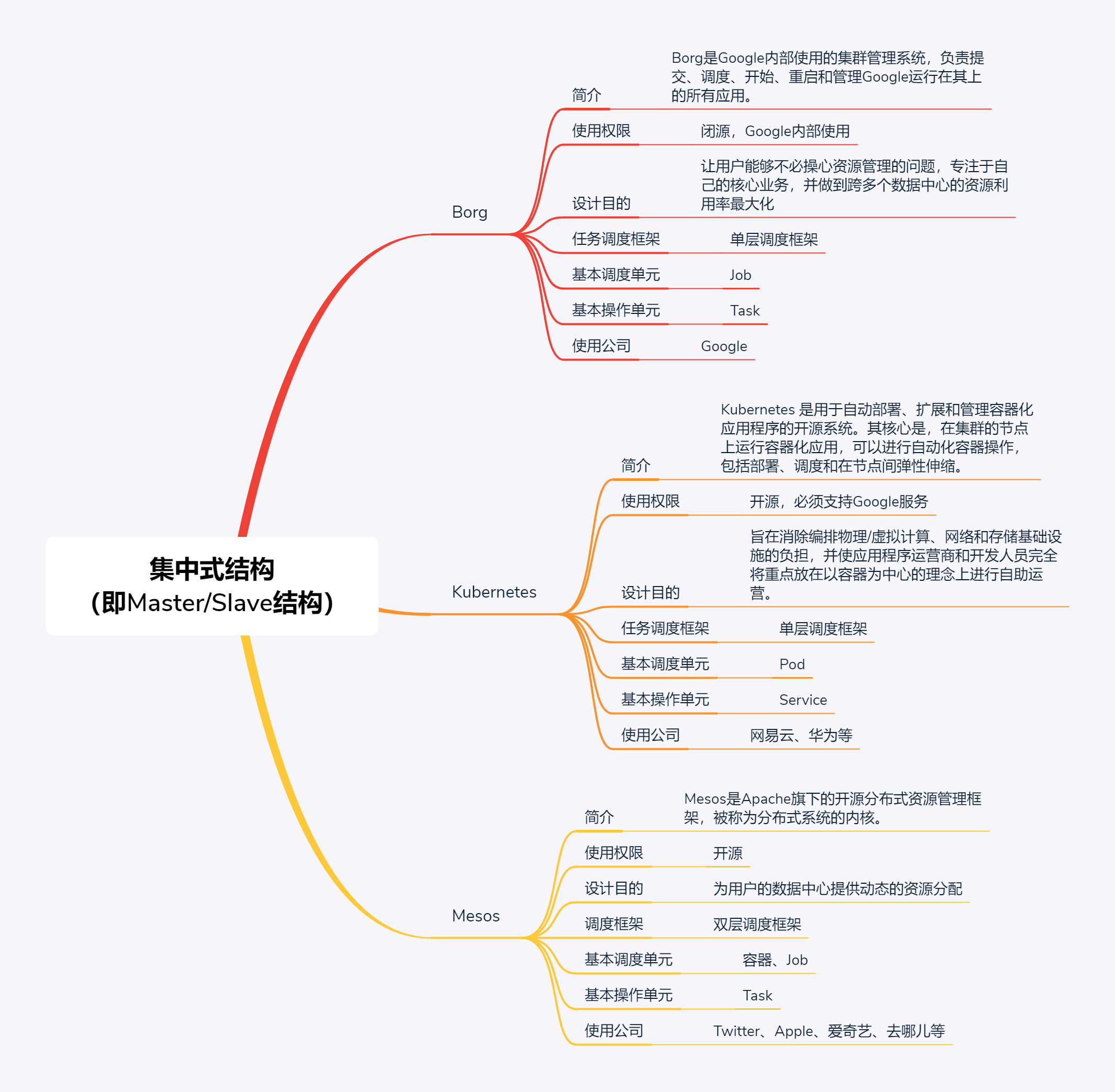
集中式结构
集中式结构就是,由一台或多台服务器组成中央服务器,系统内的所有数据都存储在中央服务器中,系统内所有的业务也均先由中央服务器处理。多个节点服务器与中央服务器连接,并将自己的信息汇报给中央服务器,由中央服务器统一进行资源和任务调度:中央服务器根据这些信息,将任务下达给节点服务器;节点服务器执行任务,并将结果反馈给中央服务器
非集中式结构
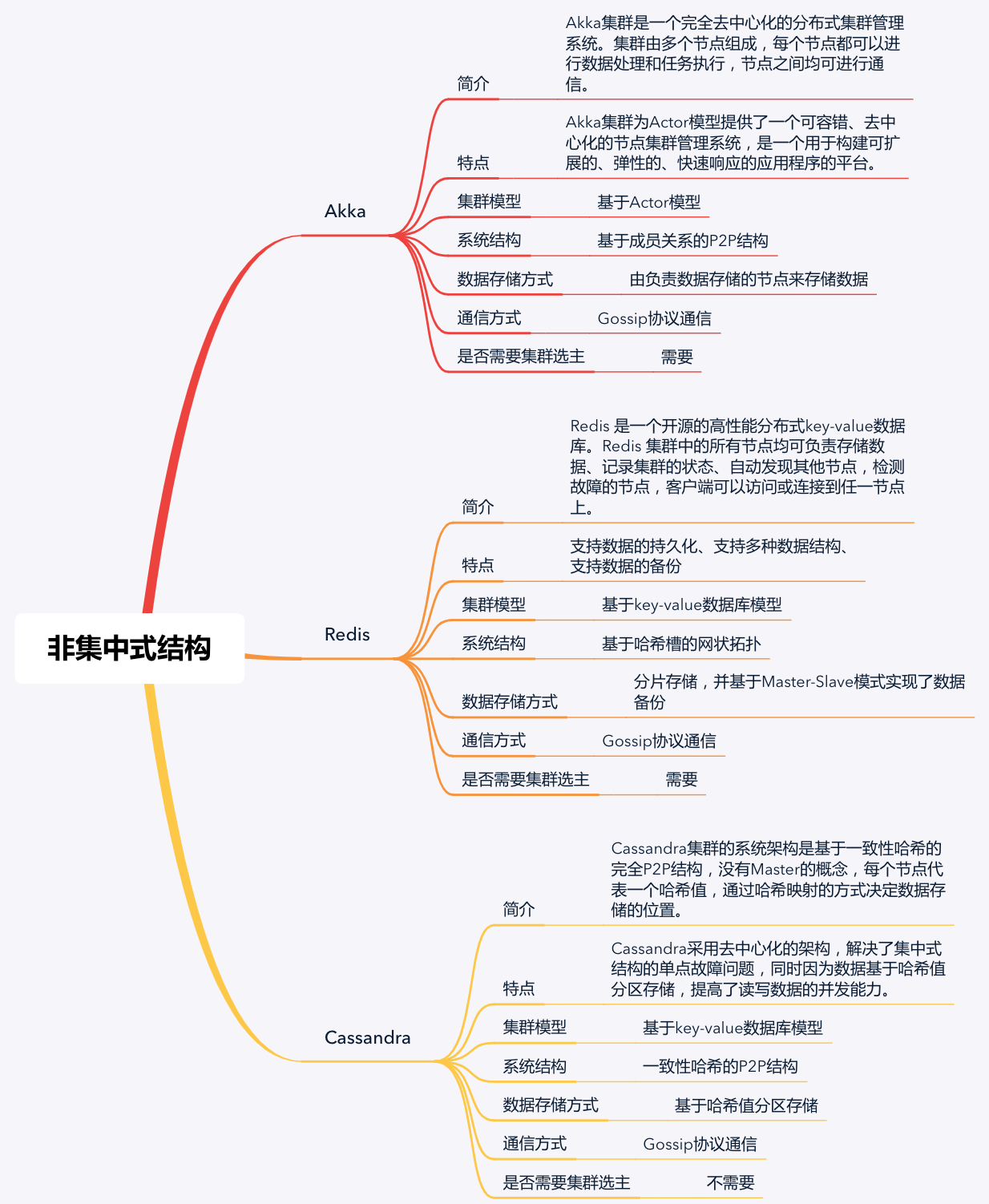
虽然很多云上的管理都采用了集中式结构,但是这种结构对中心服务器性能要求很高,而且存在单点瓶颈和单点故障问题。为了解决这个问题,分布式领域中又出现了另一经典的系统结构,即非集中式结构,也叫作分布式结构
在非集中式结构中,服务的执行和数据的存储被分散到不同的服务器集群,服务器集群间通过消息传递进行通信和协调
也就是说,在非集中式结构中,没有中央服务器和节点服务器之分,所有的服务器地位都是平等(对等)的,也就是我们常说的“众生平等”。这样一来,相比于集中式结构,非集中式结构就降低了某一个或者某一簇计算机集群的压力,在解决了单点瓶颈和单点故障问题的同时,还提升了系统的并发度,比较适合大规模集群的管理
Akka 集群、Redis 集群和 Cassandra 集群
AKKA集群
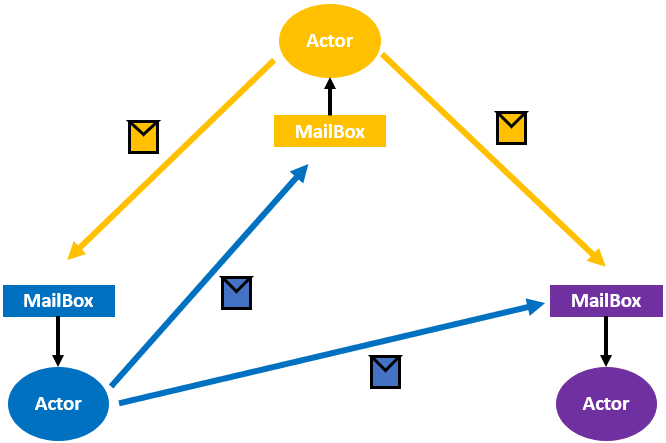
Akka 框架基于 Actor 模型,提供了一个用于构建可扩展的、弹性的、快速响应的应用程序的平台。其中,Actor 是一个封装了状态和行为的对象,它接收消息并基于该消息执行计算。Actor 之间互相隔离,不共享内存,但 Actor 之间可通过交换消息(mail)进行通信(每个 Actor 都有自己的 MailBox)。比如,在分布式系统中,一个服务器或一个节点可以视为一个 Actor,Actor 与 Actor 之间采用 mail 进行通信,
Akka 集群采用了 Gossip 协议,该协议是最终一致性协议。它的原理是每个节点周期性地从自己维护的集群节点列表中,随机选择 k 个节点,将自己存储的数据信息发给这 k 个节点,接收到该信息的节点采用前面讲的共识原则,对收到的数据和本地数据进行合并,这样迭代几个周期后,集群中所有节点上的数据信息就一致了
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/09/20/%E5%88%86%E5%B8%83%E5%BC%8F%E8%B5%84%E6%BA%90%E7%AE%A1%E7%90%86/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)