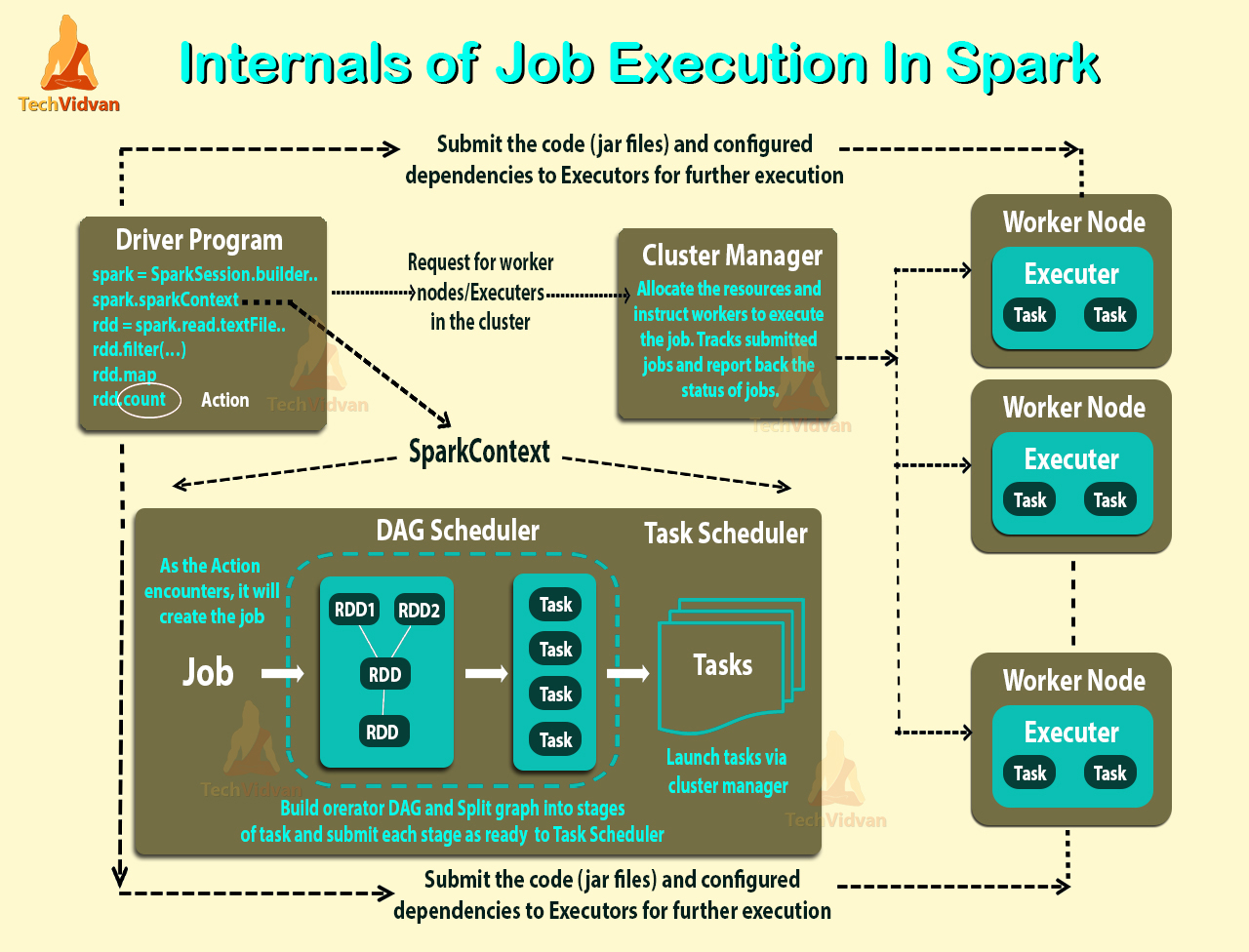
Spark 作业执行过程
Spark的特性
Speed
Spark通过多种方式追求速度的目标。
1.首先,其内部实施极大地受益于硬件行业最近在提高CPU和内存的价格以及性能方面的巨大进步。当今的商用服务器价格便宜,具有数百GB的内存,多个内核以及基于Unix的底层操作系统,它们利用了有效的多线程和并行处理的优势。对框架进行了优化,以利用所有这些因素。 2.Spark将其查询计算构建为有向无环图(DAG);它的DAG调度程序和查询优化器构建了一个高效的计算图,通常可以将其分解为在集群中的所有工作程序中并行执行的任务。
3.它的物理执行引擎Tungsten使用整个阶段的代码生成来生成紧凑的代码以供执行,由于所有中间结果都保留在内存中,并且限制了磁盘I / O的使用,这极大地提高了性能
Ease of Use
Spark通过提供简单的逻辑数据结构(称为弹性分布式数据集(RDD))的基本抽象,在其上构造所有其他更高层次的结构化数据抽象(如DataFrame和Dataset),从而实现了简化。 通过提供一组作为操作的转换和动作,Spark提供了一个简单的编程模型,您可以使用该模型来以熟悉的语言构建大数据应用程序。
Modularity
Spark操作可以应用于多种类型的工作负载,并以任何受支持的编程语言表示:Scala,Java,Python,SQL和R。Spark为统一库提供了文档完善的API,这些API包括以下模块作为核心组件 :Spark SQL,Spark结构化流,Spark MLlib和GraphX,将在一个引擎下运行的所有工作负载组合在一起。 您可以编写一个可以完成所有任务的Spark应用程序-不需要用于不同工作负载的独特引擎,也无需学习单独的API。 借助Spark,您可以获得适用于您的工作负载的统一处理引擎
Extensibility
Spark专注于其快速的并行计算引擎,而不是存储。 与包含存储和计算的Apache Hadoop不同,Spark将两者分离。 这意味着您可以使用Spark读取存储在众多源(Apache Hadoop,Apache Cassandra,Apache HBase,MongoDB,Apache Hive,RDBMS等)中的数据,并在内存中进行处理。 Spark的DataFrameReaders和DataFrame Writers也可以扩展为从其他来源(例如Apache Kafka,Kinesis,Azure Storage和Amazon S3)读取数据,并将其转换为可以在其上进行操作的逻辑数据抽象。
作为不断发展的生态系统的一部分,Spark开发人员社区维护着一个第三方Spark软件包列表。 这个丰富的软件包生态系统包括适用于各种外部数据源,性能监视器等的Spark连接器
Spark Structured Streaming
和flink差不多,在原来的spark sql上面加了个触发器,Mode也分 CompleteMode,Append Mode,Update Mode 和 Retract差不多
Spark 分布式执行方式
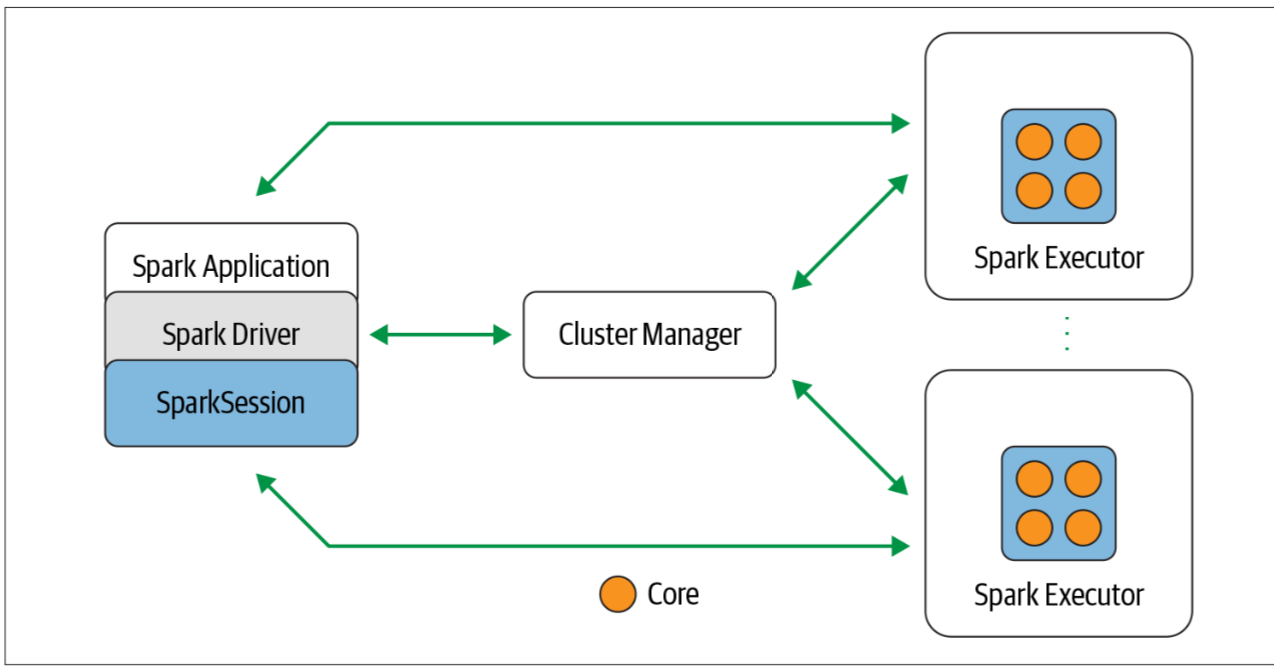
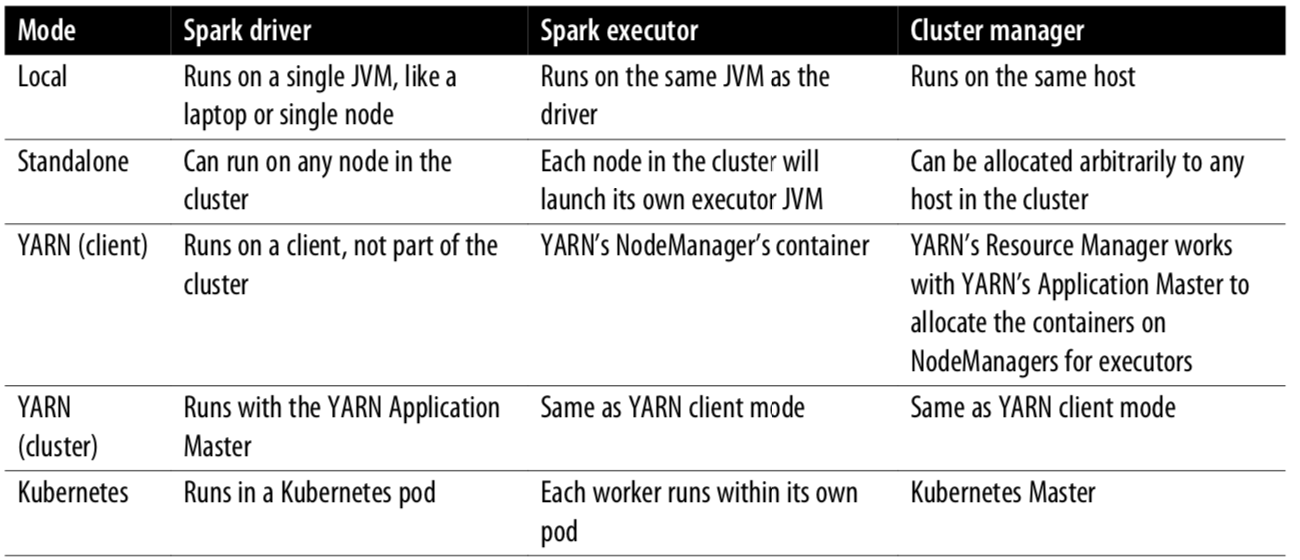
Transformations, Actions, and Lazy Evaluation
Transformations
orderBy()
groupBy()
filter()
select()
join()
Actions
show()
take()
count()
collect()
save()
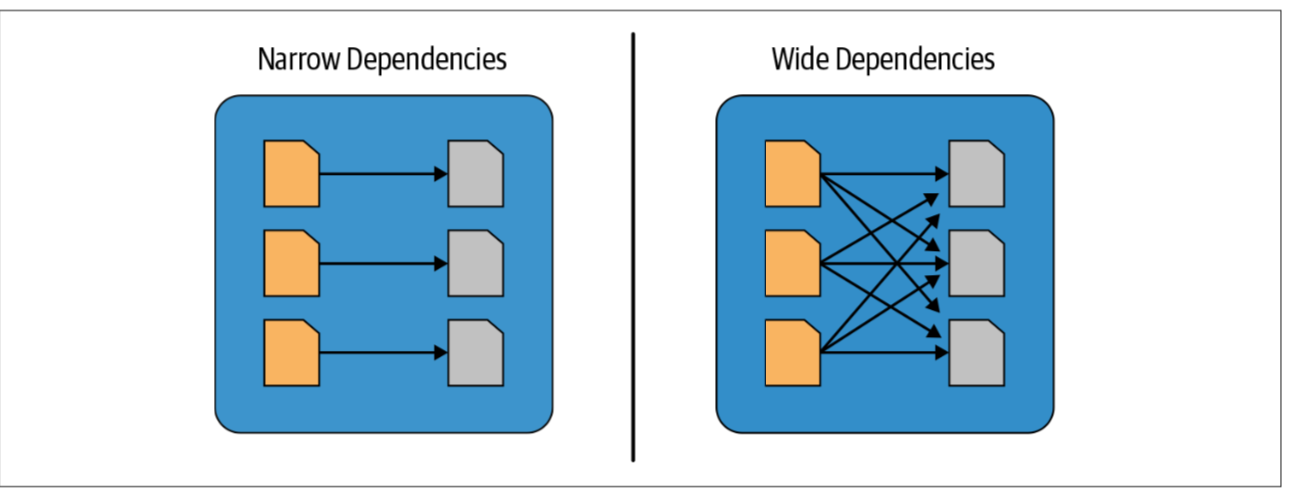
Narrow and Wide Transformations
Spark RDD
1.Dependencies
2.Partitions (with some locality information)
2.Compute function: Partition => Iterator[T]
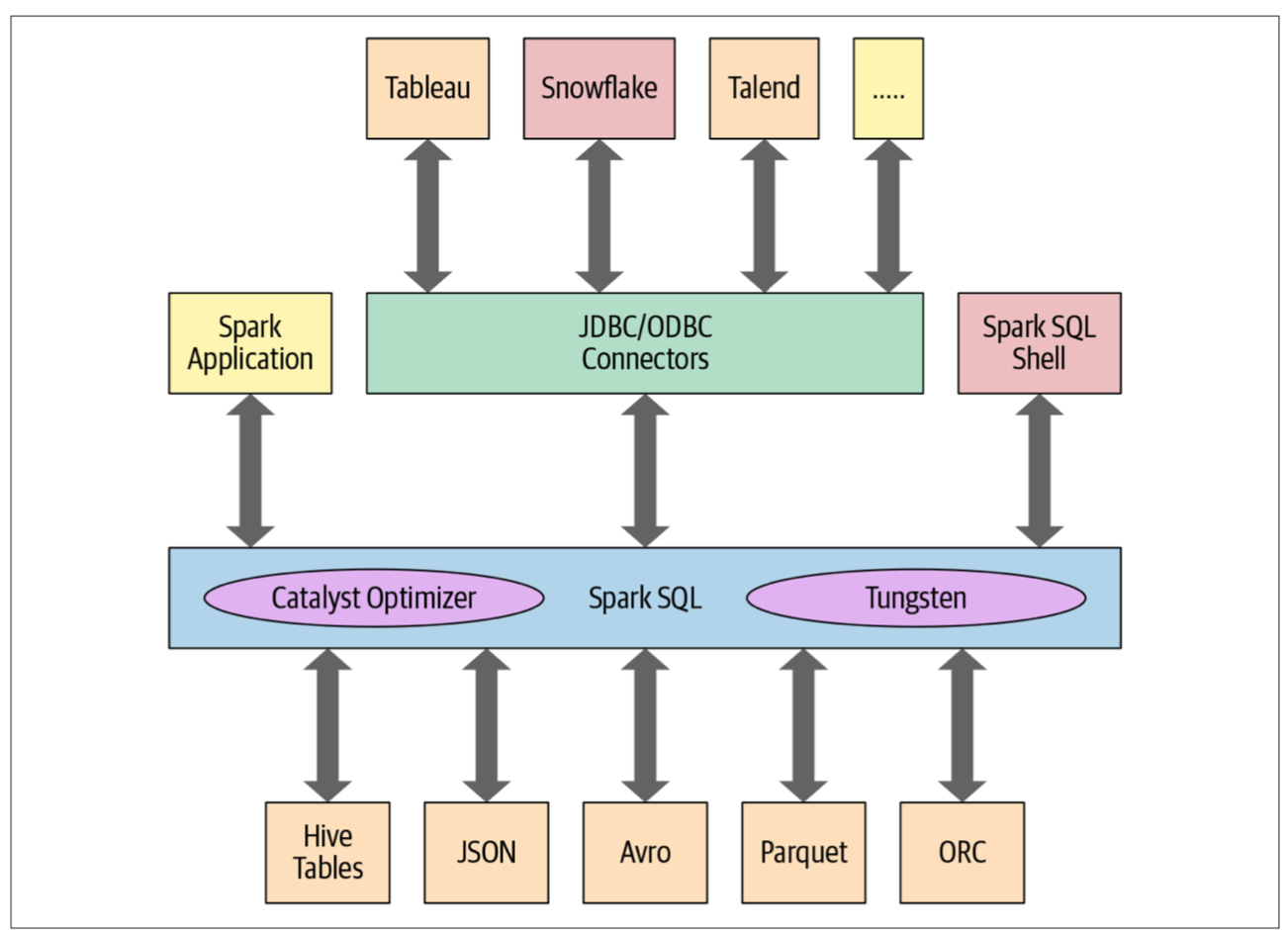
Spark SQL
The Catalyst Optimizer
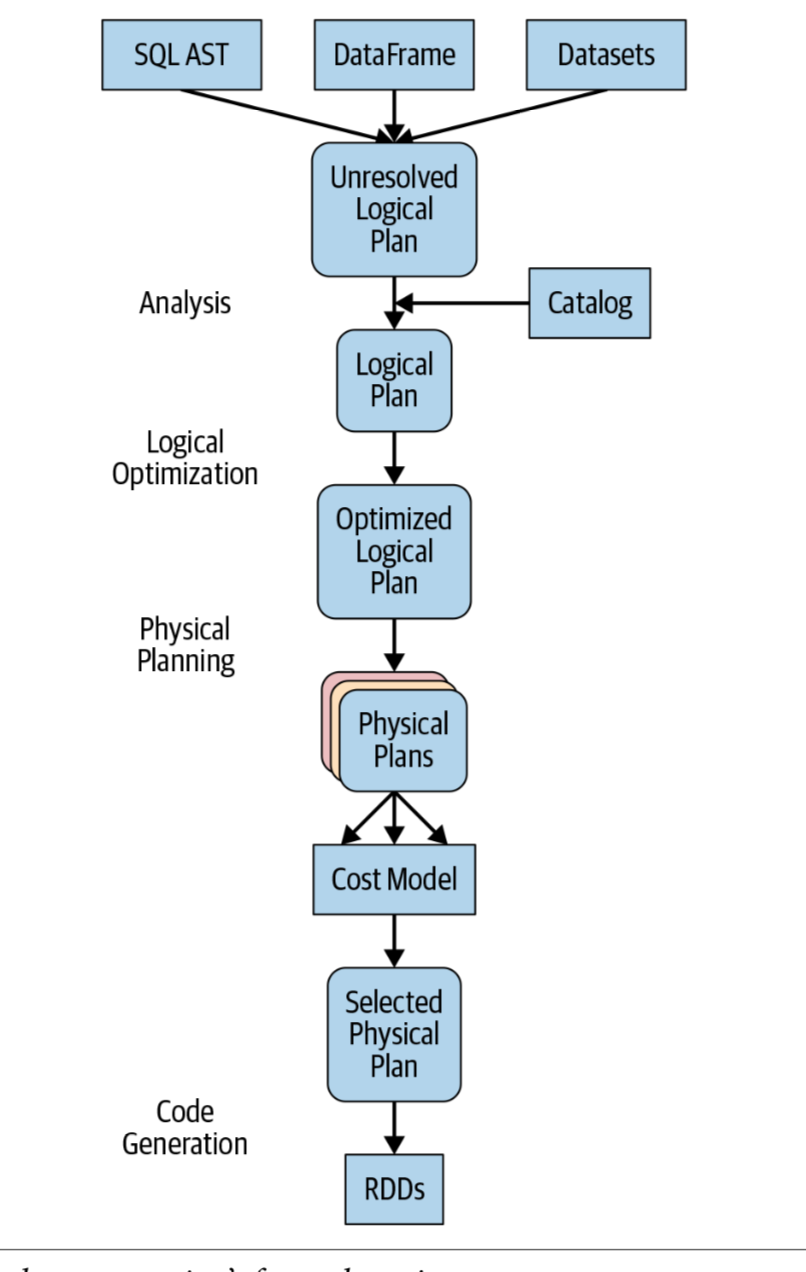
### Analysis
### Logical optimization
#### 基于规则的优化方式(Rule-Based Optimization,简称为RBO)
优化器在分析SQL语句时,所遵循的是Oracle内部预定的一些规则,对数据是不敏感的。它只借助少量的信息来决定一个sql语句的执行计划,包括:
1)sql语句本身
2)sql中涉及到的table、view、index等的基本信息
3)本地数据库中数据字典中的信息(远程数据库数据字典信息对RBO是无效的)
例如:我们常见的,当一个where子句中的一列有索引时去走索引。但是需要注意,走索引不一定就是优的,比如一个表只有两行数据,一次IO就可以完成全表的检索,而此时走索引时则需要两次IO,这时全表扫描(full table scan)的效率更优。
#### 基于代价的优化方式(Cost-Based Optimization,简称为CBO)
它是看语句的代价(Cost),通过代价引擎来估计每个执行计划所需的代价,该代价将每个执行计划所耗费的资源进行量化,CBO根据这个代价选择出最优的执行计划。一个查询所耗费的资源可分为三部分:I/O代价、CPU代价、NETWORK代价。I/O是指把数据从磁盘读入内存时所需代价(该代价是查询所需最主要的,所以在优化时一个基本原则就是降低I/O总次数);CPU代价是指处理内存中数据所需的代价,数据一旦读入内存,当我们识别出我们所要的数据后,会在这些数据上执行排序(sort)或连接(join)操作,这需要消耗CPU资源;对于访问远程节点来说,network代价的花费也是很大的。
优化器在判断是否用这种方式时,主要参照的是表及索引的统计信息。统计信息给出表的大小、有多少行、每行的长度等信息。这些统计信息起初在库内是没有的,是做analyze后才出现的,很多的时侯过期统计信息会令优化器做出一个错误的执行计划,因些应及时更新这些信息(dbms_stat.analyze)。
如星型连接排列查询,哈希连接查询,函数索引,和并行查询等一些技术都是基于CBD的
### Physical planning
### Code generation
查询优化的最后阶段涉及生成可在每台计算机上运行的有效Java字节码。 因为Spark SQL可以对内存中加载的数据集进行操作,所以Spark可以使用最新的编译器技术来生成代码以加快执行速度。 换句话说,它充当编译器。 Tungsten项目在此起到了重要作用,它有助于整个阶段的代码生成。 整个阶段的代码生成是什么? 这是一个物理查询优化阶段,它将整个查询分解为一个函数,摆脱虚拟函数调用,并使用CPU寄存器存储中间数据。 Spark 2.0中引入的第二代Tungsten引擎使用此方法生成紧凑的RDD代码以最终执行。 这种简化的策略大大提高了CPU效率和性能。
# Tungsten引擎
Project Tungsten: Bringing Spark Closer to Bare Metal
为了大幅提升Spark应用使用CPU和Memory的效率,让Spark的性能接近硬件的极限
## 内存管理与二进制处理(Memory Management and Binary Processing)
## Cache-aware计算(Cache-awareComputation)
## 代码生成(Code Generation)
https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/09/15/Spark%E5%9F%BA%E7%A1%80/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)