支持高并发,高可用,高性能的分布式消息系统
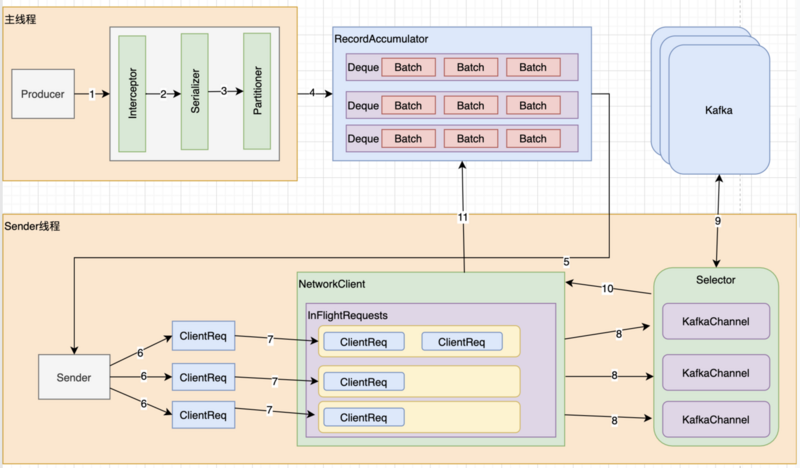
Producer生产数据的流程

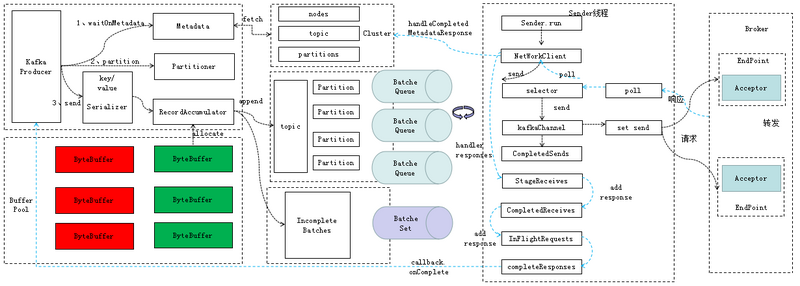
Kafka -> ProducerInterceptors(拦截器)->Serializer->Partitioner(分区器)
RecordAccumulator (Dqueue[RecordBatch])
Sender线程 去 RecordAccumulator去读取数据,封装多个ClientRequest发送给NetWorkClient,Sender线程 接收到请求 再回调 Producer 的 Callback
NetWorkClient (多个ClientRequest) 接到请求返回给 Sender线程
Selector (KafkaChannel) 发送给 Kafka集群 执行网络请求,返回响应
Sender(NetworkClient(Selector))
Acks:0: producer 发送数据到 broker后,就完了,没有返回值
1: producer发送数据到broker后,数据成功写入 leader partition 以后返回响应
-1: producer 发送数据到 broker后,数据写入到leader partition里面,并且数据同步到所有的follower partition
Sender发送消息的过程
KSelector
Broker端
broker如何接收数据(高并发)
数据写入(leader partition)
ISR 集合表示 目前可用且消息量与Leader相差不多的副本集合
副本的数据同步(HW,LEO)
HighWatermark 由Leader副本管理的,当ISR集合中全部的Followe副本都拉取HW指定消息进行同步后,Leader副本会递增HW的值
LEO (Log End Offset) 是所有副本都有个 offset的记录,表示追加到 当前副本的最后一个消息的offset
如果 所有副本都完成了对 某个offset 的消息同步,Leader副本会递增其 HW
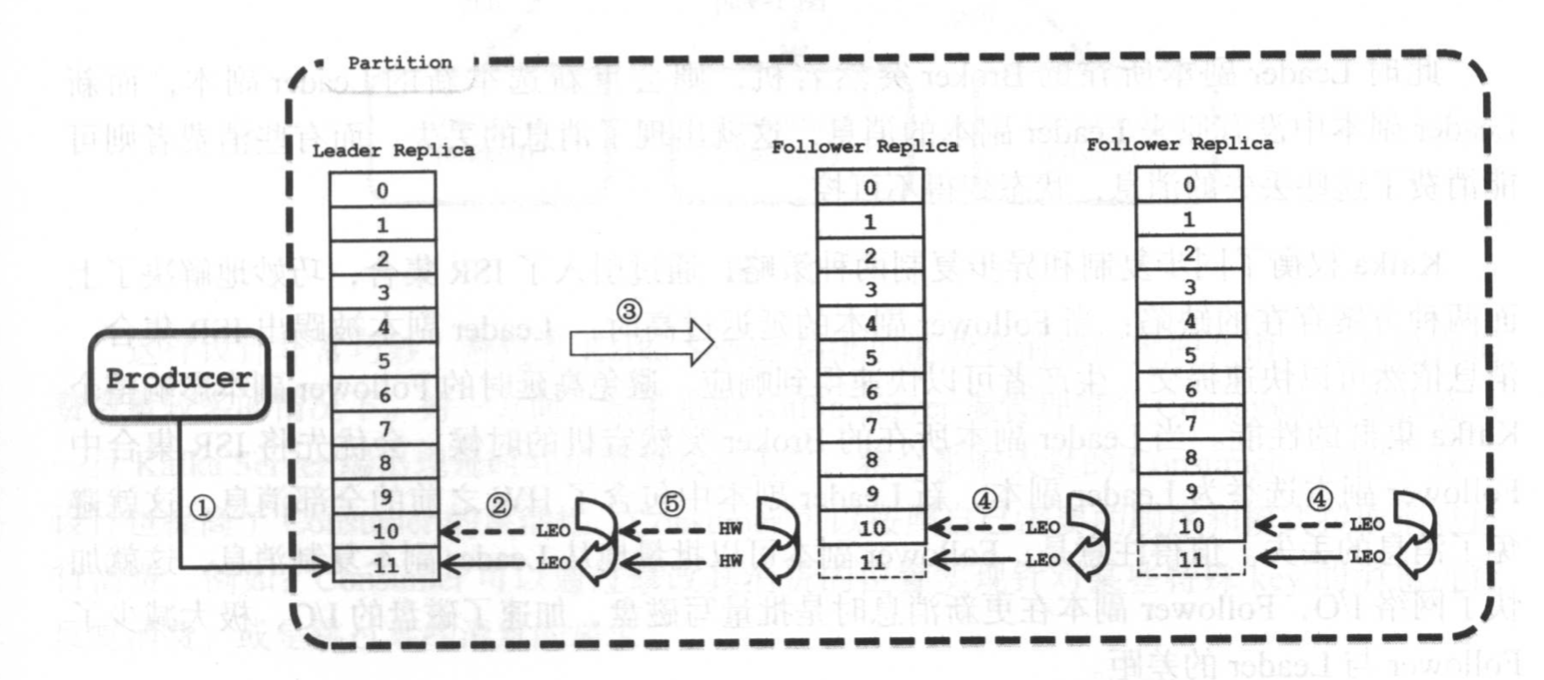
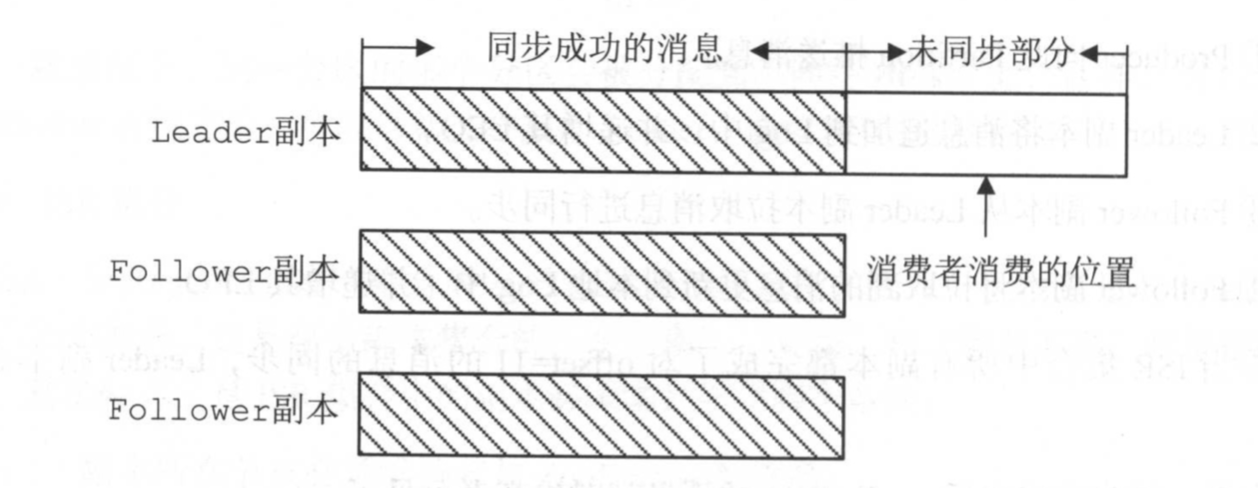
同步复制的缺点要求所有能工作的Followe副本都赋值完,故障的followe会 拖慢系统性能
异步复制的,如果leader收到消息就认为成功,如果保存消息量远远落后于Leader,Leader一旦宕机,就会出现消息丢失
Kafka权衡了 这两种策略,引入ISR集合,如果Follower延迟高就被踢出ISR,Leader宕机的话,Follower也能保存HW之前的信息
##
kafka的集群管理(controller-> zookeeper)
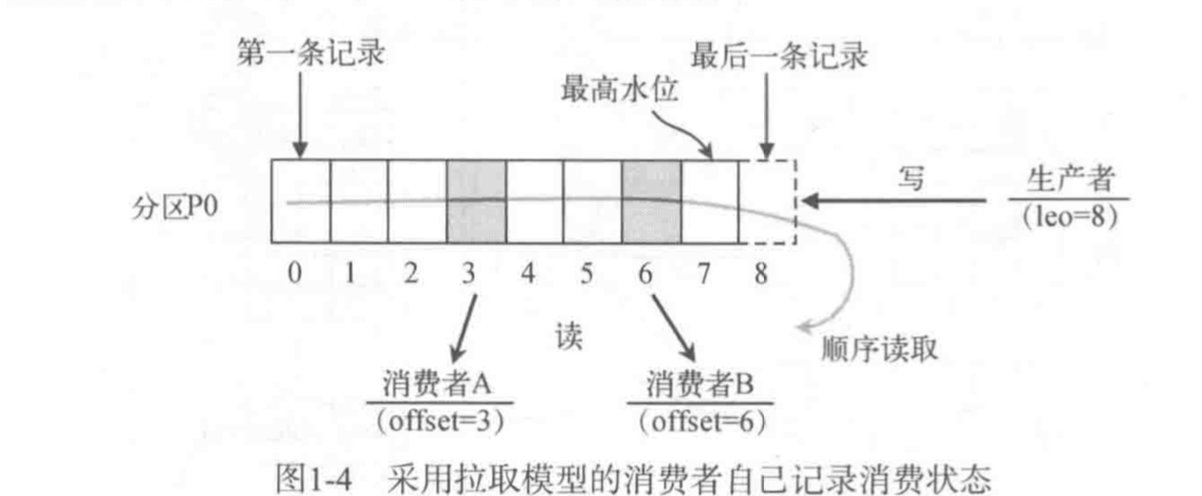
Consumer消费数据
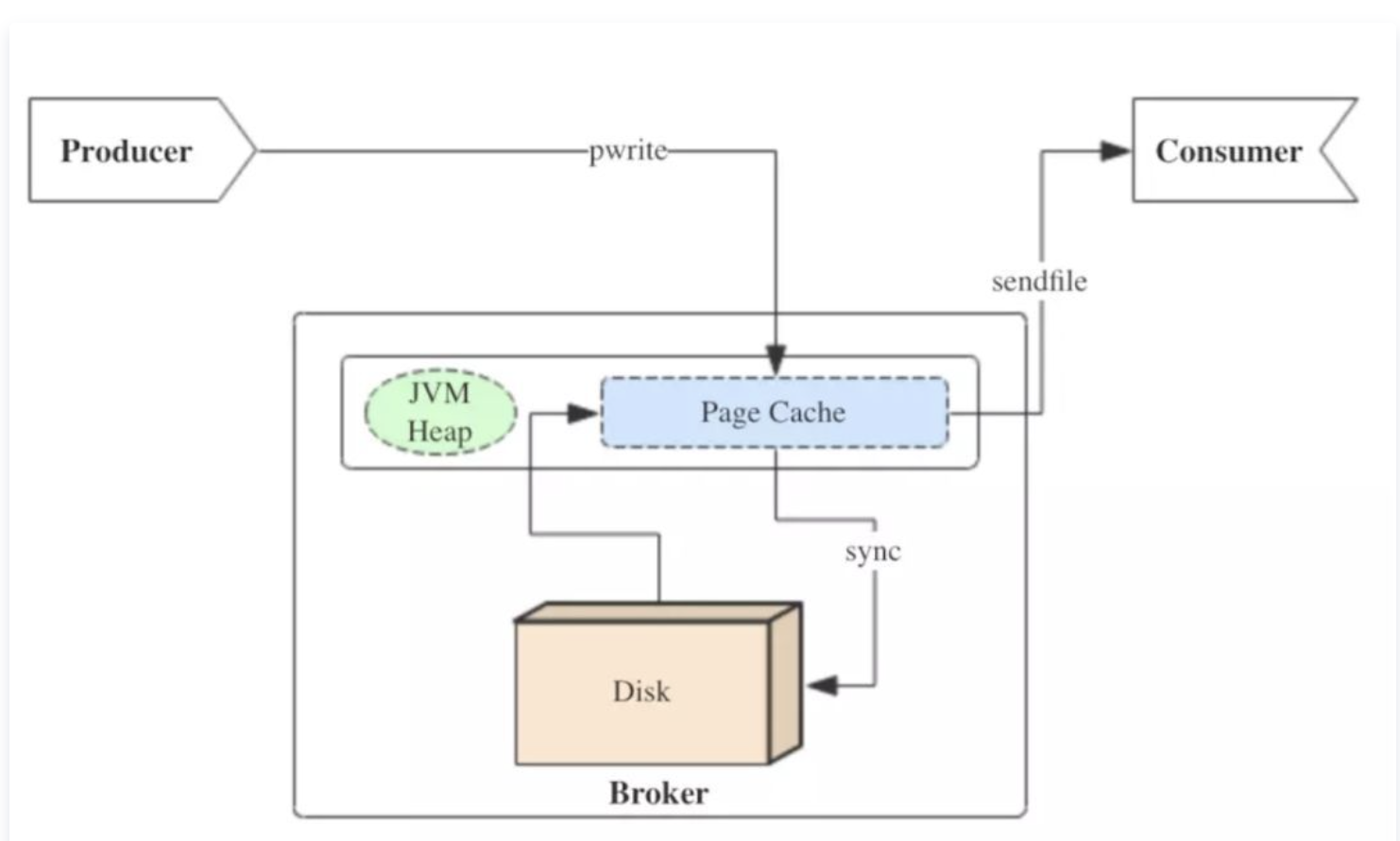
限速的实现和PageCache
producer生产消息时,会使用pwrite()系统调用【对应到Java NIO中是FileChannel.write() API】按偏移量写入数据,并且都会先写入page cache里。consumer消费消息时,会使用sendfile()系统调用【对应FileChannel.transferTo() API】,零拷贝地将数据从page cache传输到broker的Socket buffer,再通过网络传输。
内存管理机制
BufferPool.allocate负责从缓冲池中申请ByteBuffer,当缓冲区中 内存不足就会阻塞调用线程
Deallocate 负责释放线程
零Copy
在 Linux 系统中,传统的访问方式是通过 write() 和 read() 两个系统调用实现的,
传统访问方法
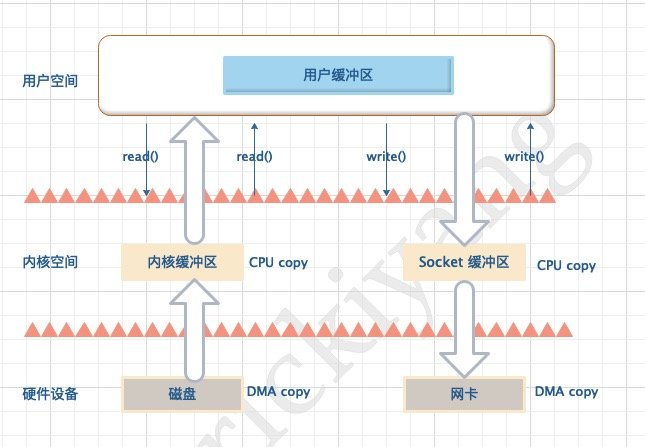
Read
read(file_fd, tmp_buf, len);
基于传统的 I/O 读取方式,read 系统调用会触发 2 次上下文切换,1 次 DMA 拷贝和 1 次 CPU 拷贝,发起数据读取的流程如下:
- 用户进程通过
read()函数向内核 (kernel) 发起系统调用,上下文从用户态 (user space) 切换为内核态 (kernel space); - CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间 (kernel space) 的读缓冲区 (read buffer);
- CPU 将读缓冲区 (read buffer) 中的数据拷贝到用户空间 (user space) 的用户缓冲区 (user buffer)。
- 上下文从内核态 (kernel space) 切换回用户态 (user space),read 调用执行返回
write
write(socket_fd, tmp_buf, len);
基于传统的 I/O 写入方式,write() 系统调用会触发 2 次上下文切换,1 次 CPU 拷贝和 1 次 DMA 拷贝,用户程序发送网络数据的流程如下:
- 用户进程通过
write()函数向内核 (kernel) 发起系统调用,上下文从用户态 (user space) 切换为内核态(kernel space)。 - CPU 将用户缓冲区 (user buffer) 中的数据拷贝到内核空间 (kernel space) 的网络缓冲区 (socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区 (socket buffer) 拷贝到网卡进行数据传输。
- 上下文从内核态 (kernel space) 切换回用户态 (user space),write 系统调用执行返回。
零拷贝方式
https://www.cnblogs.com/rickiyang/p/13265043.html
在 Linux 中零拷贝技术主要有 3 个实现思路:用户态直接 I/O、减少数据拷贝次数以及写时复制技术
- 用户态直接 I/O:应用程序可以直接访问硬件存储,操作系统内核只是辅助数据传输。这种方式依旧存在用户空间和内核空间的上下文切换,硬件上的数据直接拷贝至了用户空间,不经过内核空间。因此,直接 I/O 不存在内核空间缓冲区和用户空间缓冲区之间的数据拷贝。
- 减少数据拷贝次数:在数据传输过程中,避免数据在用户空间缓冲区和系统内核空间缓冲区之间的CPU拷贝,以及数据在系统内核空间内的CPU拷贝,这也是当前主流零拷贝技术的实现思路。
- 写时复制技术:写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么将其拷贝到自己的进程地址空间中,如果只是数据读取操作则不需要进行拷贝操作。
Sendfile
sendfile
sendfile 系统调用在 Linux 内核版本 2.1 中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程。sendfile 系统调用的引入,不仅减少了 CPU 拷贝的次数,还减少了上下文切换的次数,它的伪代码如下:
sendfile(socket_fd, file_fd, len);
通过 sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。与 mmap 内存映射方式不同的是, sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。
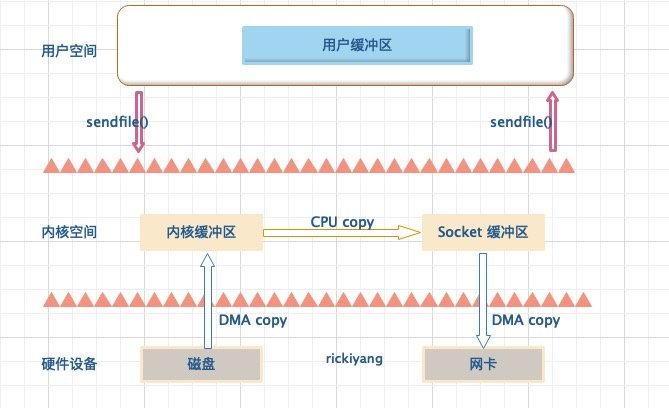
基于 sendfile 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过
sendfile()函数向内核 (kernel) 发起系统调用,上下文从用户态 (user space) 切换为内核态(kernel space)。 - CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间 (kernel space) 的读缓冲区 (read buffer)。
- CPU 将读缓冲区 (read buffer) 中的数据拷贝到的网络缓冲区 (socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区 (socket buffer) 拷贝到网卡进行数据传输。
- 上下文从内核态 (kernel space) 切换回用户态 (user space),sendfile 系统调用执行返回
| 拷贝方式 | CPU拷贝 | DMA拷贝 | 系统调用 | 上下文切换 |
|---|---|---|---|---|
| 传统方式(read + write) | 2 | 2 | read / write | 4 |
| 内存映射(mmap + write) | 1 | 2 | mmap / write | 4 |
| sendfile | 1 | 2 | sendfile | 2 |
| sendfile + DMA gather copy | 0 | 2 | sendfile | 2 |
| splice | 0 | 2 | splice | 2 |
零拷贝应用
Java NIO 中的零拷贝 - MappedByteBuffer
基于 sendfile 实现的 FileChannel
transferTo():通过 FileChannel 把文件里面的源数据写入一个 WritableByteChannel 的目的通道。
transferFrom():把一个源通道 ReadableByteChannel 中的数据读取到当前 FileChannel 的文件里面
Netty零拷贝
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/08/30/Kafka-%E6%BA%90%E7%A0%81/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)