原文链接: https://ververica.cn/developers/advanced-tutorial-2-analysis-of-network-flow-control-and-back-pressure/
跨TaskMananger反压
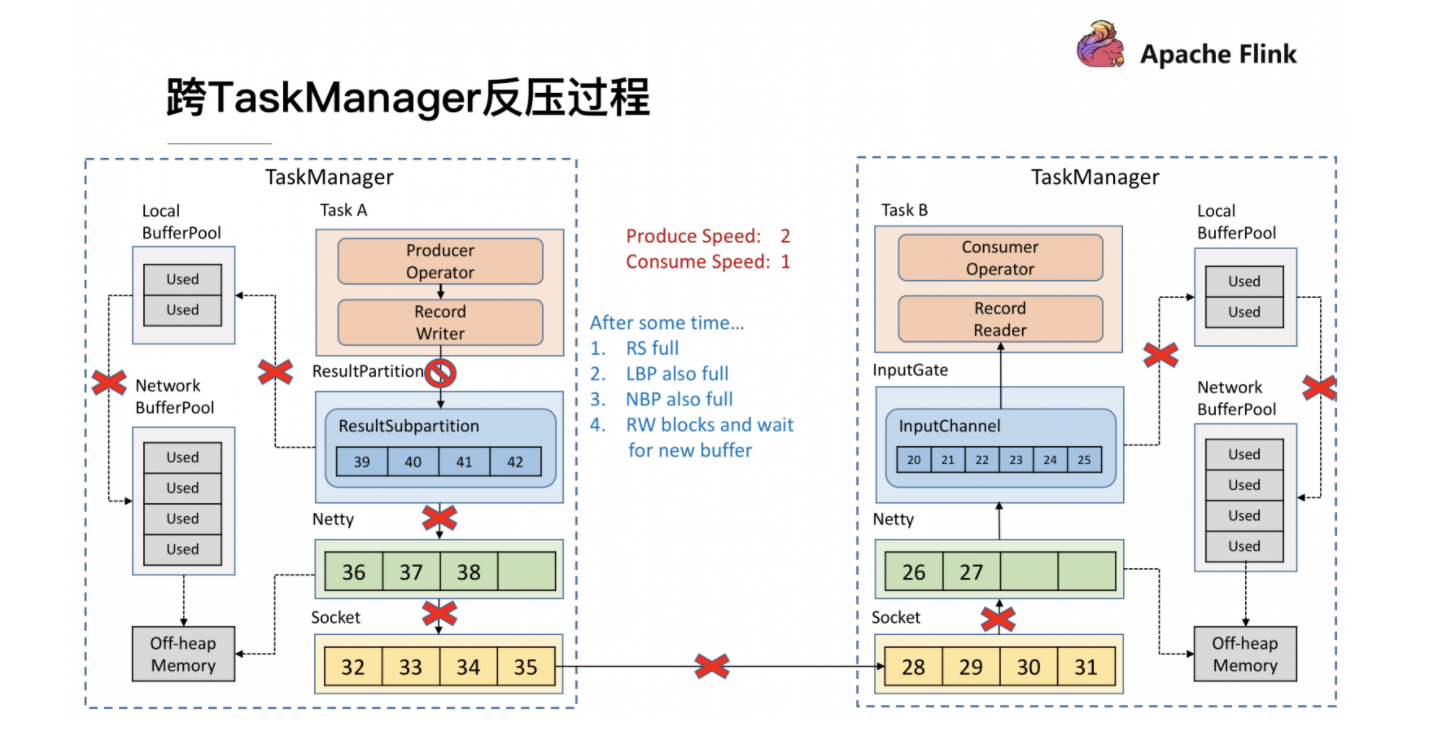
传输层直接依靠TCP协议自身具备的滑动窗口机制
内部反压过程

基于TCP的流控和反压方案有两大缺点:
只要TaskManager执行的一个Task触发反压,该TaskManager与上游TaskManager的Socket就不能再传输数据,从而影响到所有其他正常的Task,以及Checkpoint Barrier的流动,可能造成作业雪崩;
反压的传播链路太长,且需要耗尽所有网络缓存之后才能有效触发,延迟比较大
最新反压过程
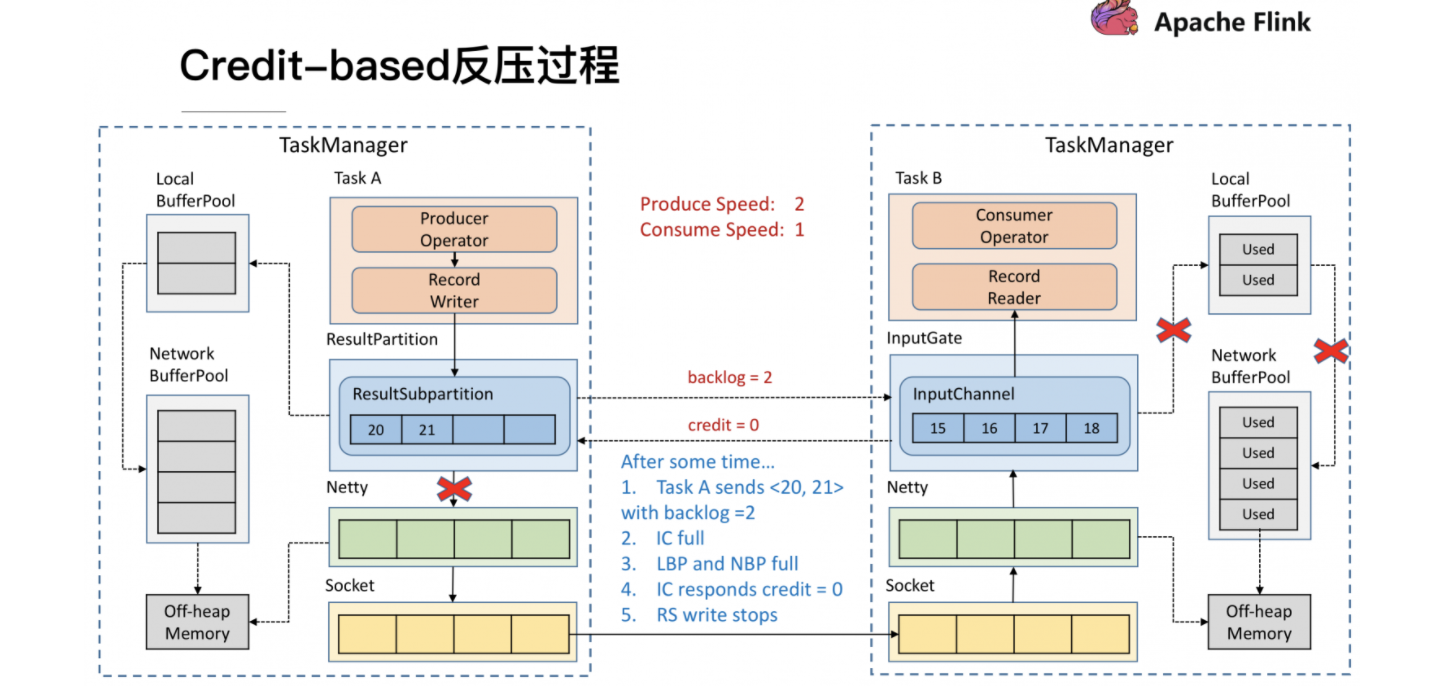
它本质上是将TCP的流控机制从传输层提升到了应用层——即ResultPartition和InputGate的层级,从而避免在传输层造成阻塞。具体来讲:
Sender端的ResultSubPartition会统计累积的消息量(以缓存个数计),以backlog size的形式通知到Receiver端的InputChannel;
Receiver端InputChannel会计算有多少空间能够接收消息(同样以缓存个数计),以credit的形式通知到Sender端的ResultSubPartition。
Sender和Receiver通过互相告知对方自己的处理能力的方式来精准地进行流控(注意backlog size和credit也是要通过传输层的,不是直接交换的)。接下来仍然通过实例来说明基于Credit的流控和反压流程
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/08/26/Flink%E5%8F%8D%E5%8E%8B/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)