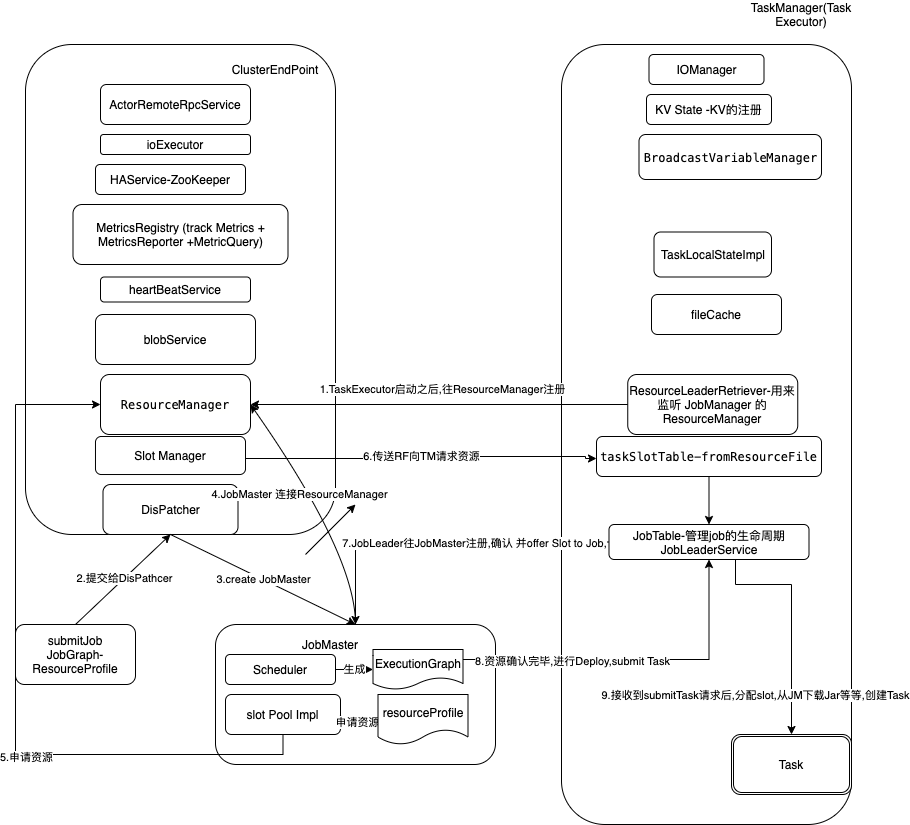
作业提交流程
Runtime模块解析
flink-runtime
accumulators
accumulatorRegistry
用来封装用户自定义 Acc
public AccumulatorRegistry(JobID jobID, ExecutionAttemptID taskID) {
this.jobID = jobID;
this.taskID = taskID;
}
Akka
OneForOneStrategy
Akka中有两个策略,分别是:OneForOneStrategy 和 AllForOneStrategy。它们都通过一个mapping将异常类型映射到不同的处理机制(stop,restart等),并且规定了它们最多可以出现异常多少次,如果次数超过了阈值就会被terminate。二者不同的是前者只针对异常的actor采用设定好的处理机制,而后者会将处理机制应用到所有的同辈(兄弟)actor。正常情况下你应该采用OneForOneStrategy,而且这也是Akka默认采用的机制。
那么什么情况下应该采用AllForOneStrategy?当一个actor和它的同辈(兄弟)actor紧密地绑定在了一起,这个actor的异常会影响到其它actor的功能时,采用AllForOneStrategy是一个不错的选择。
当使用AllForOneStrategy时,正常情况下停止一个child actor不会使得其他的child actor。如果想实现这样的效果(一个stop,其他也stop),可以采用monitoring它们的生命周期。当一个terminated消息被传递给supervision的时候,如果这个supervision不处理这个消息,这个supervision会抛出DeathPactException给上层supervision,这就会导致它的重启,在preStart方法中会终止所有它的child actor。
Blob
https://cwiki.apache.org/confluence/display/FLINK/FLIP-19%3A+Improved+BLOB+storage+architecture
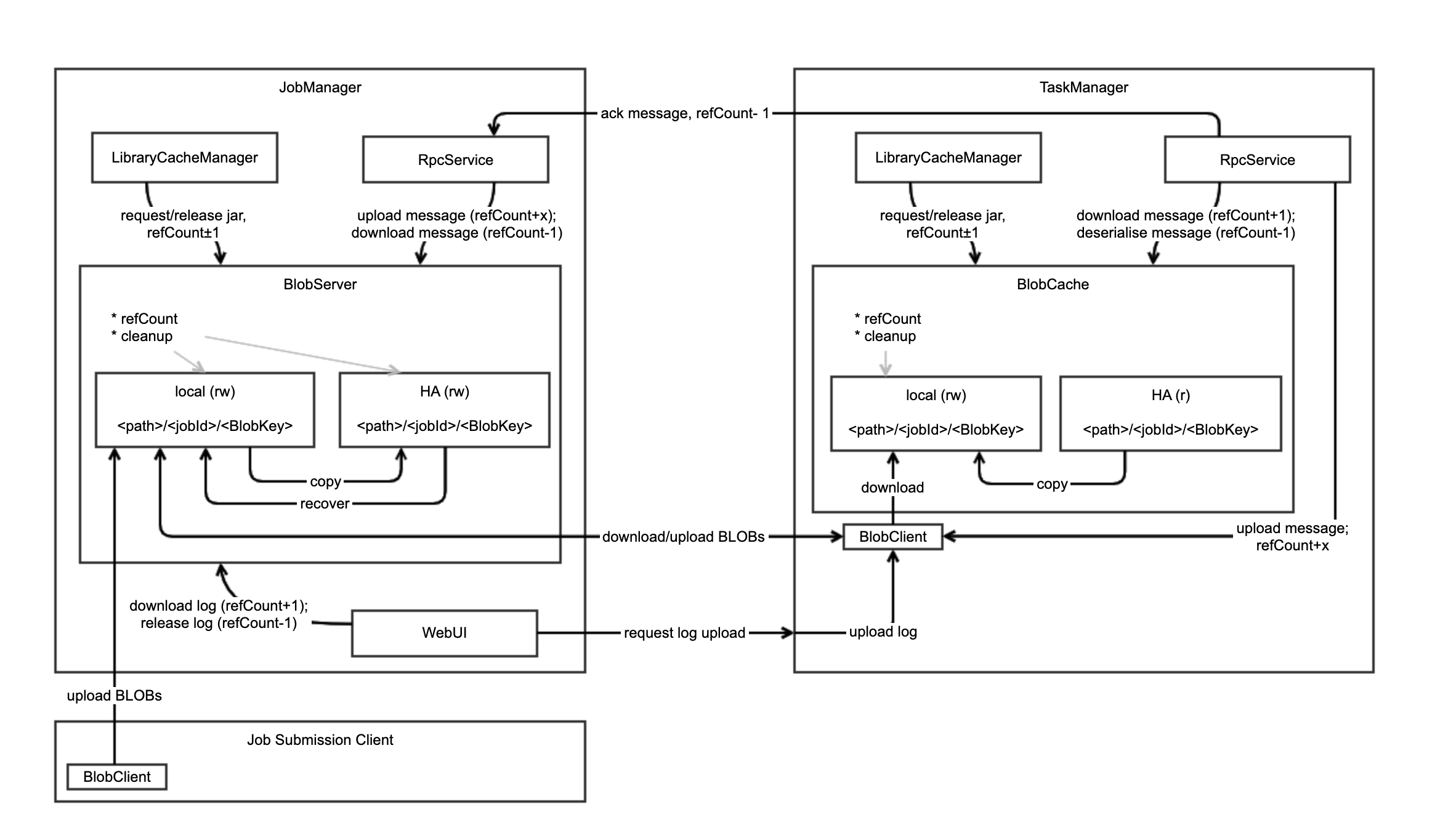
BlobServer
* 提供了基于jobId和BlobKey进行文件上传和下载的方法
* 本地文件系统的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* HA 分布式文件系统的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* 负责本地文件系统和分布式文件系统的清理工作
* 先存储到本地文件系统中,然后如果需要的话再存储到分布式文件系统中
* 下载请求优先使用本地文件系统中的文件
* 进行HA恢复中,下载分布式系统中的文件到本地文件系统中
BoardCast
BoardCastVariableMananger等
具体看 flink-streaming-java
CheckPoint
目录结构
/user-defined-checkpoint-dir
/{job-id}
|
+ --shared/
+ --taskowned/
+ --chk-1/
+ --chk-2/
+ --chk-3/
...

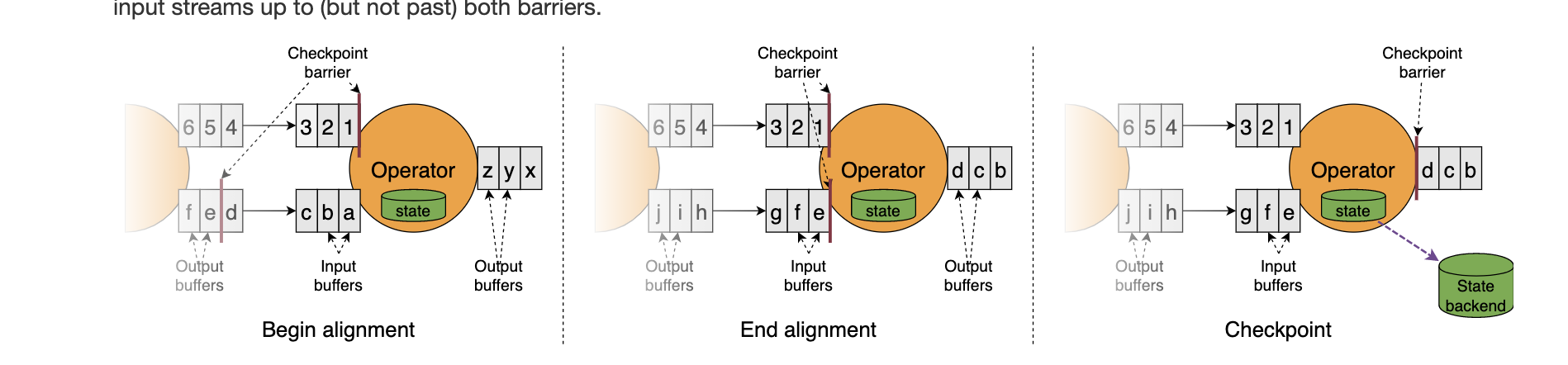
Channel
channelStateReader,channelStateWrite等
Metadata
/** The checkpoint ID. */
private final long checkpointId;
/** The operator states. */
private final Collection<OperatorState> operatorStates;
包括(OperatorID,[subtaskIndex,OpertorsubtaskState],paralleism,maxParallelism)
OperatorSubtaskState:(managedOperatorState,managedKeyedState,inputChannelState)
/** The states generated by the CheckpointCoordinator. */
private final Collection<MasterState> masterStates;(name,bytes,version)
CheckpointCoordinator
ClusterFramework
ResourceProfile
SlotProfile
TaskExecutorProcessSpec
<p>The relationships of TaskExecutor memory components are shown below.
* <pre>
* ┌ ─ ─ Total Process Memory ─ ─ ┐
* ┌ ─ ─ Total Flink Memory ─ ─ ┐
* │ ┌───────────────────────────┐ │
* ││ Framework Heap Memory ││ ─┐
* │ └───────────────────────────┘ │ │
* │ ┌───────────────────────────┐ │ │
* ┌─ ││ Framework Off-Heap Memory ││ ├─ On-Heap
* │ │ └───────────────────────────┘ │ │
* │ │┌───────────────────────────┐│ │
* │ │ │ Task Heap Memory │ │ ─┘
* │ │└───────────────────────────┘│
* │ │ ┌───────────────────────────┐ │
* ├─ ││ Task Off-Heap Memory ││
* │ │ └───────────────────────────┘ │
* │ │┌───────────────────────────┐│
* ├─ │ │ Network Memory │ │
* │ │└───────────────────────────┘│
* │ │ ┌───────────────────────────┐ │
* Off-Heap ─┼─ │ Managed Memory │
* │ ││└───────────────────────────┘││
* │ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
* │ │┌─────────────────────────────┐│
* ├─ │ JVM Metaspace │
* │ │└─────────────────────────────┘│
* │ ┌─────────────────────────────┐
* └─ ││ JVM Overhead ││
* └─────────────────────────────┘
* └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
* </pre>
Dispatcher
负责接收Job提交,持久化他,启动一个JobMananger 去执行任务
ExecutionGraph
/task /JobVertexID | ExecutionJobVertex
/currentExecution 20并发度的话就有20个 /ExecutionAttemptID | Execution Attempt #0 (source (1/10)) @ (unassigned) - [CREATED]
/executionTopology /pipelinedRegions | 0- exectionVertices
FailOver
RestartPipelinedRegionFailoverStrategy
在该策略中,“相关” region中的所有任务Vertices都将被重新启动。
涉及区域按以下规则计算:
1.包含失败任务的区域总是被牵涉进来
2.如果相关区域的输入结果分区不可用,即丢失或损坏,
包含分区生成器任务的区域被包含在内
3.如果涉及到一个region,那么它的所有consumer regions都将参与进来
RestartAllFailoverStrategy
FailureRateRestart
FixedDelayRestart
HighAvailability
zookeeper
/flink
* +/cluster_id_1/resource_manager_lock
* | |
* | +/job-id-1/job_manager_lock
* | | /checkpoints/latest
* | | /latest-1
* | | /latest-2
* | |
* | +/job-id-2/job_manager_lock
* |
* +/cluster_id_2/resource_manager_lock
* |
* +/job-id-1/job_manager_lock
* |/checkpoints/latest
* | /latest-1
* |/persisted_job_graph
Disk
IOManager
IOManager(String[] tempDirs)
NetWork
Api
Buffer
基于 MemorySegment,
NetWorkBuffer
NetWorkBufferPool 一个固定大小的池
ArrayDeque
NetworkBufferPool创建LocalBufferPool,单个任务从中提取用于网络数据传输的缓冲区。当创建新的本地缓冲池时
NetworkBufferPool在池之间动态地重新分配缓冲区。
Metrics
InputGateMetrics,InputBufferMetrics
Netty
NettyMessage,NetworkBufferAllocator
Partition
LocalInputChannel,RemoteInputChannel
JobGraph
JobManager
JobMaster
Operator
Sort join hash 等 都是离线的?
ResourceMananger
slotManager
Rpc
Akka
State
filesystem
heap
memory
metainfo
Ttl
TtlIncrementalCleanup
https://flink.apache.org/2019/05/19/state-ttl.html
private final T userValue;
private final long lastAccessTimestamp;
TaskExecutor(TaskMananger)
Task
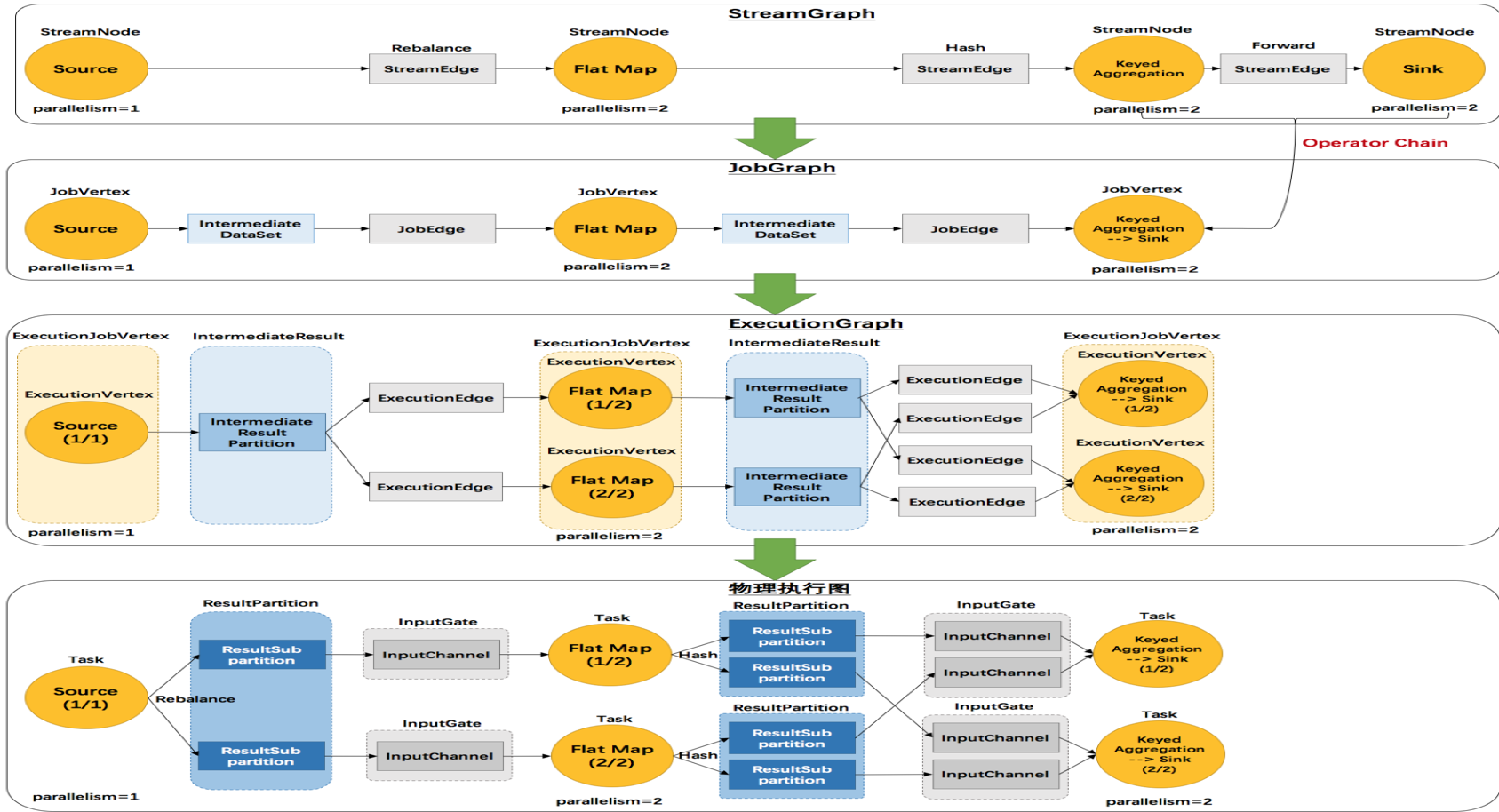
作业转化和数据流通过程
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/08/21/Flink-Runtime%E7%BB%84%E4%BB%B6/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)