flink-table-planner-blink
flink sql
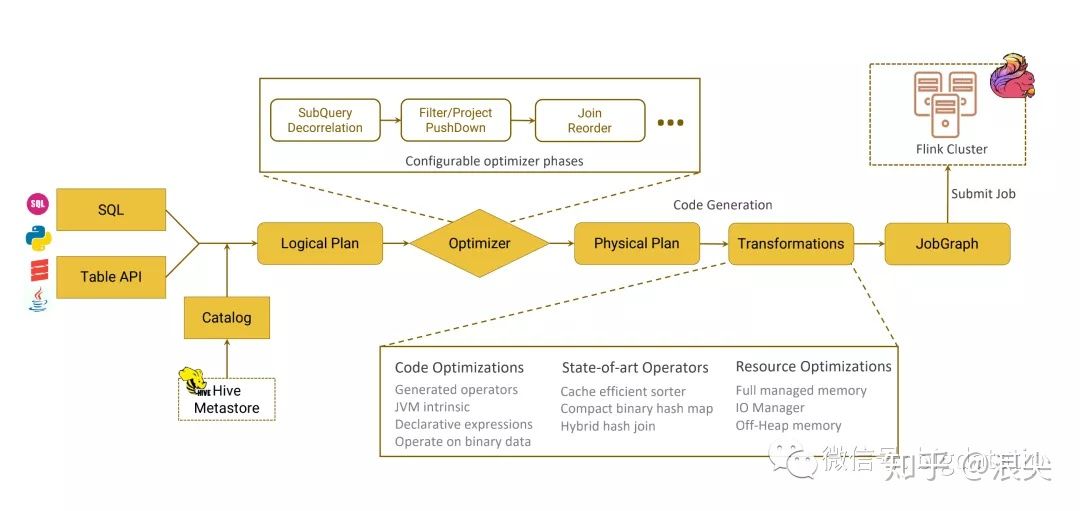
1. Sql Parser: 将sql语句通过java cc解析成AST(语法树),在calcite中用SqlNode表示AST;
2. Sql Validator: 结合数字字典(catalog)去验证sql语法;
3. 生成Logical Plan: 将sqlNode表示的AST转换成LogicalPlan, 用relNode表示;
4. 生成 optimized LogicalPlan: 先基于calcite rules 去优化logical Plan,
再基于flink定制的一些优化rules去优化logical Plan;
5. 生成Flink PhysicalPlan: 这里也是基于flink里头的rules,将optimized LogicalPlan转成成Flink的物理执行计划;
6. 将物理执行计划转成Flink ExecutionPlan: 就是调用相应的tanslateToPlan方法转换和利用CodeGen元编程成Flink的各种算子
calcite
SqlExprToRexConverter
之前在Calcite 篇有介绍 RelNode和 RexNode
我们可以通过SqlExprToRexConverter来获取RexNode从而生成代码
举例
SQL语句
SELECT ts - INTERVAL '0.001' SECOND FROM __temp_table__
通过SQL语句获取RexNode[]
@Override
public RexNode[] convertToRexNodes(String[] exprs) {
//query语句是 SELECT ts - INTERVAL '0.001' SECOND FROM __temp_table__
String query = String.format(QUERY_FORMAT, String.join(",", exprs));
//通过 Flink Planner 解析成 SqlSelect
//ts - INTERVAL '0.001' SECOND 是SqlBasicCall ts和Interval '0.001' SECOND是operands
SqlNode parsed = planner.parser().parse(query);
// validate 来校验 运算对象operands是否合法存在
SqlNode validated = planner.validate(parsed);
// SqlNode转成 RelNode,LogicalProject,input为 LogicalTableScan
RelNode rel = planner.rel(validated).rel;
// The plan should in the following tree
// LogicalProject
// +- TableScan
//再通过LogicalProject 获取每列的Row Expression 即RexNode
if (rel instanceof LogicalProject
&& rel.getInput(0) != null
&& rel.getInput(0) instanceof TableScan) {
// RexCall "-($0, 1:INTERVAL SECOND)",operands:0 RexInputRef"$0",operands:1 RexLiteral"1:INTERVAL SECOND"
return ((LogicalProject) rel).getProjects().toArray(new RexNode[0]);
} else {
throw new IllegalStateException("The root RelNode should be LogicalProject, but is " + rel.toString());
}
}
CodeGenerator工具类 通过RexNode生成当前row的java代码
val watermarkExpr: RexNode = convertToRexNodes()[0]
val generatedExpr = generator.generateExpression(watermarkExpr)
GeneratedExpression(result$3,isNull$2,
isNull$2 = isNull$1 || false;
result$3 = null;
if (!isNull$2) {
result$3 = org.apache.flink.table.data.TimestampData.fromEpochMillis(field$1.getMillisecond() - ((long) 1L), field$1.getNanoOfMillisecond());
}
,TIMESTAMP(3),None)
最后生成该节点的Function,供SingleProcessOperator调用
public final class WatermarkGenerator$0
extends org.apache.flink.table.runtime.generated.WatermarkGenerator {
public WatermarkGenerator$0(Object[] references) throws Exception {
}
@Override
public void open(org.apache.flink.configuration.Configuration parameters) throws Exception {
}
@Override
public Long currentWatermark(org.apache.flink.table.data.RowData row) throws Exception {
org.apache.flink.table.data.TimestampData field$1;
boolean isNull$1;
boolean isNull$2;
org.apache.flink.table.data.TimestampData result$3;
isNull$1 = row.isNullAt(0);
field$1 = null;
if (!isNull$1) {
field$1 = row.getTimestamp(0, 3);
}
isNull$2 = isNull$1 || false;
result$3 = null;
if (!isNull$2) {
result$3 = org.apache.flink.table.data.TimestampData.fromEpochMillis(field$1.getMillisecond() - ((long) 1L), field$1.getNanoOfMillisecond());
}
if (isNull$2) {
return null;
} else {
return result$3.getMillisecond();
}
}
@Override
public void close() throws Exception {
}
}
Catalog
可以让flink 从Calcite 查询特定的catalog
对象的全路径是 [catalog_name].[db_name].[meta-object_name]
比如要查询 hive库的表,全路径是 hive.dbname.tablename,会通过这个全路径 去查找hive metastore库下的当前table的连接信息
plan
Rules
logicalRules
logical大部分是 transformRule
比如
PushProjectIntoTableSourceScanRule
用途是 将LogicalProject 推入到 LogicalTableScan内计算
实现如下:
LogicalTableScan
-- LogicalProject
super(operand(LogicalProject.class,
operand(LogicalTableScan.class, none())),
/**
match方法
**/
matches方法中进行条件匹配,条件符合可进行转换,
只要Source支持SupportsProjectionPushDown即可
tableSourceTable.tableSource() instanceof SupportsProjectionPushDown
/**
onMatch方法
**/
onMatch 中进行 transformTo
LogicalTableScan newScan = new LogicalTableScan(
scan.getCluster(), scan.getTraitSet(), scan.getHints(), newTableSourceTable);
// rewrite input field in projections
List<RexNode> newProjects = RexNodeRewriter.rewriteWithNewFieldInput(project.getProjects(), usedFields);
LogicalProject newProject = project.copy(
project.getTraitSet(),
newScan,
newProjects,
project.getRowType());
if (ProjectRemoveRule.isTrivial(newProject)) {
// drop project if the transformed program merely returns its input
call.transformTo(newScan);
} else {
call.transformTo(newProject);
}
Physical
是个 ConvertRules
computeSelfCost 从flinkplanner获取 FlinkLogical 继承trait FlinkRelNode
RuleSet to translate calcite nodes to flink nodes
举例
StreamExecPythonCorrelateRule
The physical rule is responsible for convert {@link FlinkLogicalCorrelate} to
* {@link StreamExecPythonCorrelate}.
translateToPlanInternal 方法转换成DataStream
Trait
FlinkRelDistribution
ModifyKind for changelog
/**
* Insertion operation.
*/
INSERT,
/**
* Update operation.
*/
UPDATE,
/**
* Deletion operation.
*/
DELETE
Metadata
ModifiedMonotonicity 单调性 来优化算子 比如 max with retract 和 increasing 优化成 max
/**
* Optimize max or min with retraction agg. MaxWithRetract can be optimized to Max if input is
* update increasing.
*/
def getNeedRetractions(
groupCount: Int,
needRetraction: Boolean,
monotonicity: RelModifiedMonotonicity,
aggCalls: Seq[AggregateCall]): Array[Boolean] = {
val needRetractionArray = Array.fill(aggCalls.size)(needRetraction)
if (monotonicity != null && needRetraction) {
aggCalls.zipWithIndex.foreach { case (aggCall, idx) =>
aggCall.getAggregation match {
// if monotonicity is decreasing and aggCall is min with retract,
// set needRetraction to false
case a: SqlMinMaxAggFunction
if a.getKind == SqlKind.MIN &&
monotonicity.fieldMonotonicities(groupCount + idx) == SqlMonotonicity.DECREASING =>
needRetractionArray(idx) = false
// if monotonicity is increasing and aggCall is max with retract,
// set needRetraction to false
case a: SqlMinMaxAggFunction
if a.getKind == SqlKind.MAX &&
monotonicity.fieldMonotonicities(groupCount + idx) == SqlMonotonicity.INCREASING =>
needRetractionArray(idx) = false
case _ => // do nothing
}
}
}
Nodes
Optimize
FlinkHepProgram
FlinkVolcanoProgram
expressions
ConverterRule
Codegen
包括有aggCodeHandler,WatermarkGeneratorCodeGenerator 等
举例
Agg算子 有两个重要的参数 needRetract,needMerge ,会根据当前算子Retract Mode的模式和MicroBatch 优化的特性,来确定Agg算子是否需要needRetract和needMerge
可以看一下 Spark Native Codegen
AggsHandlerCodeGenerator
Dataview
Flink-table-runtime-blink
Data
BinaryRowData
1.完全基于二进制数据
2.与内存管理紧密结合,CPU缓存友好
3.避免大量反序列化开销 直接通过MemroySegment调用类的native接口
4.大幅提升流批作业性能
Row
内部是object[] fields
1.java对象的空间开销高
2.主类型的装箱拆箱开销
3.昂贵的 反序列化
Runtime
Dataview
原本的Agg函数不能 注册自定义状态, 中间的结果只能存在用户定义的Acc内存中。
导致
1.每次处理数据,需要对整个状态进行序列化和反序列化
2.中间结果增长很容易超过 分配的内存限制并触发OOM
文档信息
- 本文作者:Jessica
- 本文链接:https://jessica0530.github.io/2020/08/20/flink-table-blink/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)